全连接神经网络#
\(\hspace{1.5em}\) 在本章中,我们将讨论全连接神经网络(Fully Connected Neural Network),也被称为多层感知机(Multi-Layer Perception,MLP),是深度学习中最基础、最核心的模型之一。 首先,全连接神经网络是深度学习的基础架构,通过多层非线性变换实现了强大的特征学习和函数逼近能力,能够拟合复杂的输入输出关系,为后续更复杂的网络结构(如CNN、RNN)提供了理论和技术基础。 其次,它在传统机器学习任务中表现优异,如图像分类、语音识别、自然语言处理等,尤其在结构化数据的建模(如金融预测、推荐系统)中具有广泛的应用。尽管CNN和Transformer等架构在特定领域表现更优,但全连接层仍是这些模型中不可或缺的组成部分,例如用于最终的特征映射或分类决策。此外,全连接神经网络推动了反向传播算法和梯度下降优化技术的发展,这些训练方法已成为现代深度学习的核心。同时,它的可解释性相对较强,便于分析模型行为,因此在医疗、金融等需要可解释性的领域仍具有重要价值。 尽管其参数量大、计算成本较高,但全连接神经网络仍然是深度学习研究和应用的重要工具,为人工智能的发展奠定了坚实基础。
\(\hspace{1.5em}\) 该模型与经典的逻辑回归模型具有相通之处,故我们将首先讨论逻辑回归模型,并引入输入层、输出层以及神经元等基本概念。随后,我们将依托只有一个隐藏层的全连接神经网络,详细介绍模型训练的关键步骤向后传播。最后,我们将简单讨论具有多个隐藏层的全连接神经网络模型。
\(\hspace{1.5em}\) 在上一章中,我们已经对逻辑回归模型进行了简单的介绍。简而言之,在给定模型一组参数 \(\btheta=(b,\bw\trans)\trans\) 时,针对一个特征向量 \(\bx\),我们需要计算
向前传播
线性运算:\(z = b + \bx\trans\bw\),
非线性变换(激活):\(a = \sigma(z)\)。
损失函数:\(-\{y\log a + (1-y)\log(1-a)\}\)
\(\hspace{1.5em}\) 我们将给定参数下,计算模型输出值以及损失函数值的过程称为向前传播(Forward propagation)。我们将特征向量 \(\bx\) 所在的“层”称为输入层。为了简化表达,我们将 “线性运算” 与“激活运算”两个操作放在同一“层”中。对于逻辑回归模型而言,“激活运算”的结果即为模型预测的概率值,我们称该层为输出层。逻辑回归模型的运算过程可用下图表示。
\(\hspace{1.5em}\) 在上图中,我们称同时含有线性运算``+``与非线性变换``\(\sigma\)``的结构为一个神经元。在这个角度讲,逻辑回归模型可以认为是只有一个神经元的神经网络模型。在下一节中,我们将拓展该模型,并讨论具有一个隐藏层的神经网络模型。
单一隐藏层神经网络--基于一个样本点#
\(\hspace{1.5em}\) 在本节中,我们首先基于一个样本点\((\bx,y)\),探讨神经网络的前向传播和后向传播机制,并介绍其对应的向量化结果。随后,我们将已经讨论的内容拓展到更为一般的具有\(n\)个样本点训练集的情况。记特征向量为\(\bx = (x_1,\ldots,x_d)\trans\in\mathbb{R}^d\)。不失一般性,在本节中,我们仍然考虑二分类问题,即\(y\in\{0,1\}\),并假设\(d=3\),隐藏层中神经元的个数为\(d^{[1]}=4\),输出层的神经元个数为\(d^{[2]}=1\)1输出层对应的是具有特征 \(\bx\) 的标签属于某一特定类别的概率。;即在本节中,我们考虑如下图所示的包含\(L=2\)层神经网络模型。
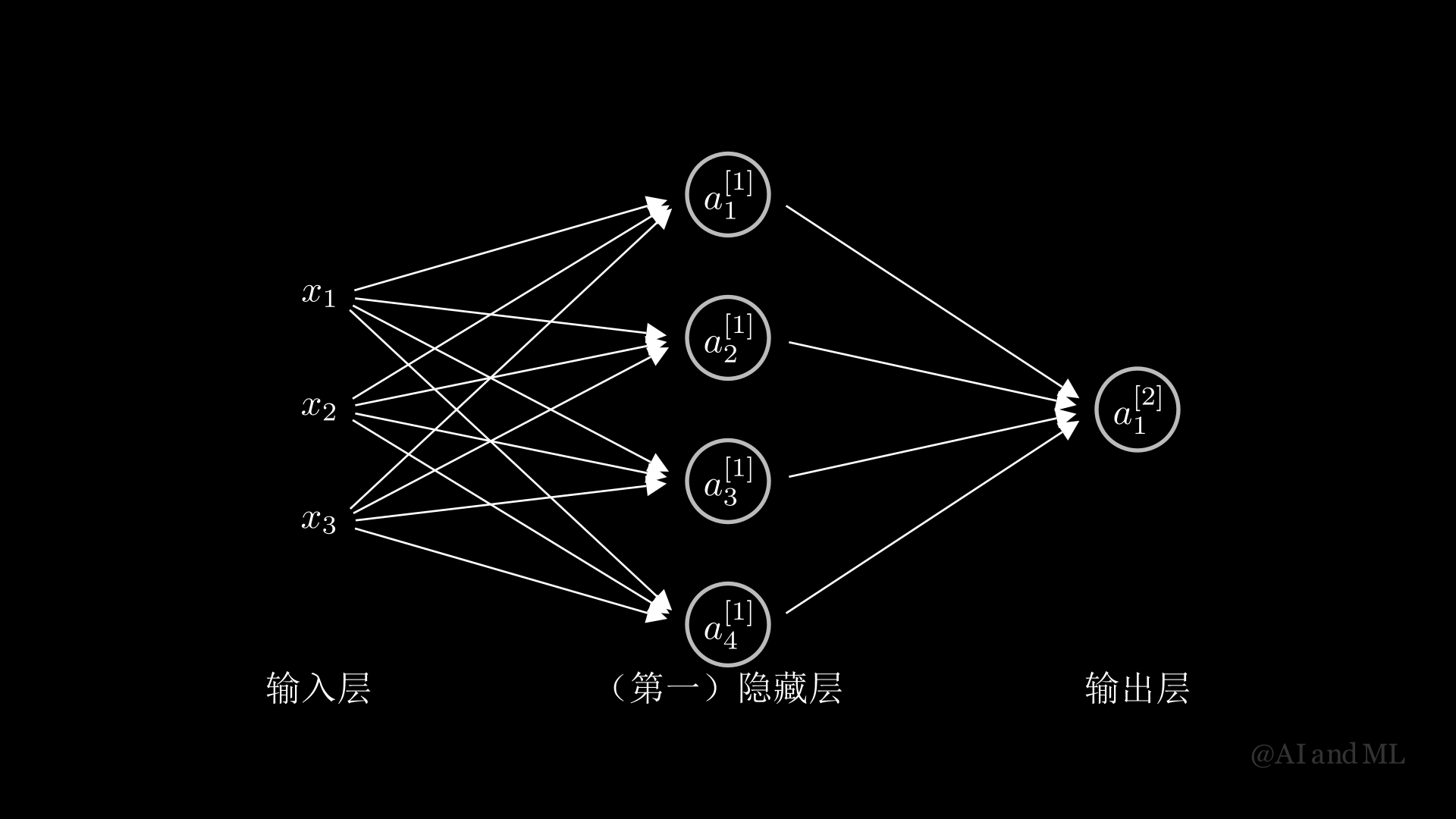
图 1 只有一个隐藏层的全连接神经网络#
备注
\(\hspace{1.5em}\) 在本课程中,我们通常用上角标表示神经元所在层,下角标表示对应神经元在该层的位置。例如, \(a_3^{[1]}\) 表示第一(隐藏)层中的第三个神经元,\(a_1^{[2]}\) 表示第二层中的第一个神经元。我们默认输入层为第0层,故 \(a_i^{[0]}=x_i\)。记 \(d^{[l]}\) 为第 \(l\) 层中神经元的总数,且记 \(d^{[0]}=d\)。 此外,与逻辑回归模型不同,神经网络模型通过引入隐藏层来充分挖掘特征中的信息。例如,在图 1所示的模型中,第一(隐藏层)利用四个神经元(利用不同的模型参数)分别提取输入特征的不同信息。数据特征 \(\bx\) 是第一(隐藏)层的输入特征,而第一(隐藏)层计算得到的结果可被视为第二层的“输入”特征。由于第二层所用到的非线性变换为 sigmoid 函数,该层可认为是将第一(隐藏层)作为输入特征的逻辑回归模型。
\(\hspace{1.5em}\) 本节所涉及到的模型训练步骤为:
基于当前模型参数,前向传播计算神经网络各神经元的值以及对应的损失函数值。
后向传播,计算损失函数对当前参数的偏导数。
利用梯度下降法,依据当前学习率进行参数更新。
回到第2步,直至参数收敛或者损失函数不再明显下降。
\(\hspace{1.5em}\) 接下来,我们将依次对上述步骤进行剖析,并在本节的最后讨论如何对模型参数进行初始化。
前向传播#
\(\hspace{1.5em}\) 首先,我们将具体讨论图 1中展示模型的前向传播计算过程。正如我们在上一节所讨论的那样,每个神经元包含线性变换和非线性变换(激活)两步运算,且不同神经元都对应着不同的偏置项和权重项。记 \(b_j^{[l]}\) 和 \(\bw_j^{[l]}\) 分别为神经元 \(a_j^{[l]}\) 所对应的(当前的)偏置项和权重项2根据我们在上一节中所讨论的符号规则,第 \(t\) 步更新后的模型参数应该表达为 \(b_j^{[l](t)}\) 和 \(\bw_j^{[l](t)}\),但为了简化符号表达,我们在本节中将上角标"\((t)\)"忽略。。
\(\hspace{1.5em}\) 当神经网络的层数 \(l\) 为正整数时,为了计算神经元 \(a_j^{[l]}\) 在当前参数下的数值,我们通常将其上一层的结果 \(\{a_j^{[l-1]}:j=1,\ldots,d^{[l-1]}\}\) 作为该神经元的输入值。例如,对于 \(j=1,\ldots,d^{[1]}\),当我们计算 \(a_j^{[1]}\) 时,对应的输入特征为 \(\{a_j^{[0]}:j=1,\ldots,d^{[0]}\} =\{x_j:j=1,\ldots,d\}\)。此时,\(a_1^{[1]}\) 的计算过程为
\(\hspace{1.5em}\) 更一般地,记 \(\ba^{[l]} = (a_1^{[l]},\ldots,a_{d^{[l]}}^{[l]})\trans\),则第 \(l\) 层的神经元 \(a_j^{[l]}\) 的计算规则如下:
通过以上计算我们可知,图 1中展示的神经网络模型的参数为每个神经元所对应的偏置项和权重项
需要指出的是,每个偏置项的维度均为1,但对应于神经元 \(a_j^{[l]}\) 的权重项 \(\bw_j^{[l]}\) 的维度为 \(d^{[l-1]}\)。该神经网络前向传播的计算流程如下图所示。
\(\hspace{1.5em}\) 为了提高模型的计算效率,我们需要对上述计算进行向量化。对于神经网络的第 \(l\) 层,记 \(\bb^{[l]} = (b_1^{[l]},\ldots,b_{d^{[l]}}^{[l]})\trans\) 以及 \(\bW^{[l]} = (\bw_1^{[l]},\ldots,\bw_{d^{[l]}}^{[l]})\trans\)。对于 \(l=1,\ldots,L\) 以及 \(j=1,\ldots,d^{[l]}\), \(\bb^{[l]}\) 和 \(\bW^{[l]}\) 中的第 \(j\) 行代表着第 \(l\) 层第 \(j\) 个神经元对应的偏置项和权重项。基于新定义的符号,我们可以得到 \(\ba^{[l]}\) 的向量化表达式3对应于 \(\ba^{[l]}\),其输入特征为 \(\ba^{[l-1]}\)。
其中,对于向量 \(\bz=(z_1,\ldots,z_m)\trans\in\mathbb{R}^m\),定义 \(\sigma(\bz)=(\sigma(z_1),\ldots,\sigma(z_m))\trans\)4对应于Python的NumPy包所涉及的广播机制。,\(m\in\mathbb{N}\) 为任意正整数。
\(\hspace{1.5em}\) 由于我们只有一个样本点 \((\bx,y)\),对应于图 1所展示的神经网络模型,基于向量化的前向传播计算过程为
需要指出的是,\(a^{[2]}\) 为模型参数 \(\btheta\) 的函数,其对应签属于类别1的条件概率。对应的损失函数为
\(\hspace{1.5em}\) 以上计算结果对应的计算图如下图所示。
备注
\(\hspace{1.5em}\) 前向传播的过程是基于当前参数计算神经网络各个神经元的结果。该过程有以下两个用途:
模型参数训练过程中,前向传播主要用于计算每个神经元在当前参数下的激活值,并计算相应的损失函数。前向传播为计算损失函数对参数的求导提供中间结果。
模型参数训练完毕后,前向传播用于计算并输出模型的估计结果。
后向传播#
\(\hspace{1.5em}\) 当我们训练模型时,我们需要根据当前参数,计算损失函数对模型参数的偏导数,并利用梯度下降法对模型参数进行一步迭代更新。例如,对模型参数\(\bb^{[1]}\) 的更新过程如下:
其中, \(\bb^{[1](t)}\) 为模型当前(即第 \(t\) 步更新后的)参数,\(\alpha\) 为算法当前学习率5算法学习一般会随着更新次数 \(t\) 的增加而降低,我们将在后面的讲解中对这个问题进行讨论。,\(\btheta\) 包含了 (20)中展示的模型所有参数,\(\mathcal{J}(\btheta^{(t)})\) 为模型在参数 \(\btheta^{(t)}\) 时的损失函数。
\(\hspace{1.5em}\) 与上一节的处理类似,为了符号的简化,我们将忽略掉表示迭代次数的上角标"\(^{(t)}\)"。在本节中,我们主要分析二分类问题。对于回归问题或者其他问题,我们只需更改神经网络模型的输出以及对应的损失函数即可。我们仍然针对一个样本点 \((\bx,y)\),考虑图 1所展示的神经网络模型,其对应的模型参数为 \(\btheta = \{\bb^{[1]},\bW^{[1]},\bb^{[2]},\bW^{[2]}\}\),对应的损失函数参见 (22)。
备注
\(\hspace{1.5em}\) 后向传播的数学基础为链式法则(Chain Rule),该法则是微积分中的一个重要结论,用于求解复合函数的导数。 如果函数 \(f(x)\) 是由两个或多个函数复合而成的,比如 \(f(x) = g\{h(x)\}\)。 那么,在一般条件下,\(f(x)\) 的导数 \(f'(x)\) 可以通过链式法则求得。当函数 \(g\) 和 \(h\) 都是一元函数时, 基于链式法则的求导结果如下(忽略自变量):
其中,\((g\circ h)\) 表示函数 \(g\{h(x)\}\)。更具体地,如果 \(f(x) = g\{h(x)\}\),我们有
其中, \(g'\{h(x)\}\) 表示函数 \(g\) 在 \(h(x)\) 处的导数,而 \(h'(x)\) 表示函数 \(h\) 在 \(x\) 处的导数。
\(\hspace{1.5em}\) 当 \(h: \mathbb{R}^p\to\mathbb{R}^d\) 以及 \(g:\mathbb{R}^d\to\mathbb{R}\) 时,复合函数 \(f= g\circ h: \mathbb{R}^p\to\mathbb{R}\)。则对 \(\bx\in\mathbb{R}^p\),我们有如下结果
其中,\(h_j = h_j(\bx)\) 为函数 \(h\) 的第 \(j\) 个分量,\(\partial f/\partial h_j\) 是将函数 \(f\) 看做向量 \((h_1,\ldots,h_d)\trans\) 的函数时对其第 \(j\) 个分量求导的结果。
\(\hspace{1.5em}\) 首先,我们以求解 \(\partial \mathcal{J}/\partial b^{[2]}\) 为例探讨后向传播的基本原理。根据前向传播的计算图,基于参数 \(b^{[2]}\) 的计算结果为 \(z^{[2]}\)。因此,我们可将中间变量 \(z^{[2]}\) 视为参数 \(b^{[2]}\) 的函数,而损失函数 \(\mathcal{J}\) 可以被视为中间变量 \(z^{[2]}\) 的函数。为了求解损失函数对参数 \(b^{[2]}\) 的导数,我们可将损失函数 \(\mathcal{J}(\btheta)\) 视为复合函数形式 \(J\circ z^{[2]}\),其中自变量为 \(b^{[2]}\)。则根据链式法则,我们有如下计算结果
根据(21)计算结果可知,
进一步根据链式法则,我们可知
式(25)中所涉及的两个偏导数也可根据(21)计算结果求得,即
\(\hspace{1.5em}\) 类似地,我们可以求出损失函数对于其他三个参数的偏导数。
备注
\(\hspace{1.5em}\) 通过 \(\partial \mathcal{J}/\partial b^{[2]}\) 的求解过程可以得到如下结论:为了计算损失函数对于参数 \(b^{[2]}\) 的偏导数,我们可根据链式法则将计算拆分成若干部分,并基于前向传播的计算结果(21)进行逐步求解。
后向传播计算结果
\(\hspace{1.5em}\) 综上,我们需要基于(21)进行后向传播,即损失函数对参数的“反向求导”。以下结果包括两部分:第一部分为“神经元”之间的后向传播,第二部分为相应“神经元”对模型参数的后向传播结果。
主要“神经元”的后向传播结果为:
“神经元”对模型参数的后向传播结果为:
其中 \(\be_j = (0,\ldots,0,1,\ldots,0)\trans\in\mathbb{R}^{d^{[1]}}\) 表示第 \(j\) 个分量为1,其他分量为0的列向量。
\(\hspace{1.5em}\) 在以上结果中,由于 \(\bz^{[1]}\) 通常对应于一个长度大于1的向量,而 \(\bW^{[1]}\) 通常对应于一个矩阵,故 \(\partial \bz^{[1]}/\partial \bW^{[1]}\) 是没有意义的。在对参数求导过程中,我们仅需计算 \(\bz^{[1]}\) 的每个分量对 \(\bW^{[1]}\) 的偏导数即可。
\(\hspace{1.5em}\) 经过代数运算,我们可得到如下梯度结果:
其中,\(\bD\) 表示由 \(\{a_j^{[1]}(1-a_j^{[1]}):j=1,\ldots,d^{[1]}\}\) 所生成的对角阵。
备注
\(\hspace{1.5em}\) 给定当前参数值,为了计算损失函数在当前参数下的偏导数(27),我们仅需要 缓存 \(\ba^{[1]}\) 以及 \(a^{[2]}\) 两个结果即可。
\(\hspace{1.5em}\) 后向传播以及梯度计算的总结如下图所示。
\(\hspace{1.5em}\) 因此,基于当前参数 \(\bb^{[1](t)}\)、 \(\bW^{[1](t)}\)、\(b^{[2](t)}\) 以及 \(\bW^{[2](t)}\),一步更新后的结果为:
其中,\(\btheta^{(t)}=\{\bb^{[1](t)},\bW^{[1](t)},b^{[2](t)},\bW^{[2](t)}\}\)。
再看后向传播#
\(\hspace{1.5em}\) 在本节中,我们进一步对比两个后向传播模块。通过对比下面两个模块,我们不难发现:基于本节结论,后向传播是以模块化的形式进行的,每个模块中进行着类似的运算。
输出层
习题#
考虑图 1中的网络结构,令\(\bx=(0.1,-0.2,0.2)\trans\)以及\(y=1\),完成如下前向传播函数的编写。
1.1 基于标准正态分布随机初始化模型参数\(\btheta = \{\bb^{[1]},\bW^{[1]},\bb^{[2]},\bW^{[2]}\}\)。(请注意参数的维度)
1.2 完成前向传播并输出在当前参数下\(\ba^{[1]}\)、\(a^{[2]}\)以及损失函数\(J(\btheta)\)的值。
1 x = np.array([0.1, -0.2, 0.2]).reshape([3, 1])
2 y = 0
3
4 def initialization(seed_num)
5 # seed_num: 随机种子
6 np.random.seed(seed_num)
7
8 # 基于标准正态分布
9 b1 =
10 W1 =
11 b2 =
12 W2 =
13 par = {'b1':b1, 'W1': W1, 'b2': b2, 'W2':W2} # 模型参数组成的字典
14
15 return par
16
17 def forward(x,y,par):
18 # x:样本点的特征
19 # y:样本对应的标签
20 # par:字典,包含当前模型参数
21
22 # 完成该函数
23 z1 =
24 a1 =
25 z2 =
26 a2 =
27 J =
28
29 return a1,a2,J
30 par = initialization(1)
31 a1,a2,J = forward(x,y,par)
32 print("The current loss is "+str(J))
基于(27)中的结果,完成如下反向传播函数的编写。
2.1 基于当前参数计算梯度
2.2 利用梯度下降法完成参数更新
1 par = initialization(1)
2 a1,a2,J = forward(x,y,par)
3
4 def derivatives(x, y, par, a1, a2):
5 # x:样本点的特征
6 # y:样本对应的标签
7 # par:字典,包含当前模型参数
8 # a1:当前模型参数参数下,隐藏层的激活值
9 # a2:当前模型参数参数下,输出层的激活值
10
11 # 完成该函数
12 db2 =
13 dW2 =
14 D =
15 db1 =
16 dW1 =
17
18 grad = {'db2':db2, 'dW2':dW2, 'db1':db1, 'dW1':dW1}
19 return grad
20
21 def update(par,grad,alpha)
22 # par:字典,包含当前模型参数
23 # grad:字典,包含当前参数下损失函数对模型参数的梯度结果
24 # alpha:学习率
25
26 # 完成该函数
27 par['W1'] -=
28 par['b1'] -=
29 par['W2'] -=
30 par['b2'] -=
31
32 return par
33
34 grad = derivatives(x, y, par, a1, a2)
35 par = update(par,grad,alpha)
36 print("The updated b1 is "+str(par['b1']))
验证(27)中的结果。
单一隐藏层神经网络--一般形式#
\(\hspace{1.5em}\) 在上一节中,我们基于一个样本点介绍了神经网络的前向传播、后向传播以及基于梯度下降法的参数更新过程。在本节中,我们将基于 \(n\) 个样本点的一般情况,讨论针对二分类问题的全连接神经网络模型。记训练集为 \(\{(\bx_i,y_i):i=1,\ldots,n\}\),其中 \(\bx_i\in\mathbb{R}^d\),\(y_i\in\{0,1\}\)。我们考虑在上一节图 1所示的神经网络模型,并针对一般情况讨论前向传播和后向传播两个过程。我们首先回顾下上一节所涉及的模型参数及其维度。
模型参数
\(\bb^{[1]}\in\mathbb{R}^{d^{[1]}\times 1}\) 为隐藏层中每个神经元对应的偏置项,每一行对应一个神经元,该层共有 \(d^{[1]}\) 个神经元。
\(\bW^{[1]}\in\mathbb{R}^{d^{[1]}\times d}\) 为隐藏层中每个神经元对应的权重项,每一行对应一个神经元。
\(b^{[2]}\in\mathbb{R}^{\textcolor{red}{1\times1}}\) 为输出层神经元对应的偏置项,本层共有一个神经元。
\(\bW^{[2]}\in\mathbb{R}^{\textcolor{red}{1}\times d^{[1]}}\) 为输出层神经元对应的权重项。
\(\hspace{1.5em}\) 需要指出的是,我们将神经网络中的每个参数都表达成了二维矩阵。这样做有助于借助于广播机制对本节所涉及到的向量化进行讨论。
前向传播#
\(\hspace{1.5em}\) 与上一节 (21) 类似,在给定当前模型参数时,我们需要针对每个训练样本计算前向传播各个“神经元”的函数值。即对于 \(i=1,\ldots,n\),计算
对应的损失函数为
其中, \(a_i^{[2]}\) 为模型参数\(\btheta\)的函数,对应于第 \(i\) 个训练样本的输出,即给定特征 \(\bx_i\) 时,对应标签属于类别1的概率。
\(\hspace{1.5em}\) 与单一训练样本点的情况不同,我们在(31)考虑平均损失函数。由于损失函数中涉及求和运算,我们需要进一步考虑向量化提高模型的计算效率。记 \(\bX=(\bx_1,\ldots,\bx_n)\trans\in\mathbb{R}^{n\times d}\) 和 \(\bY= (y_1,\ldots,y_n)\trans\in\mathbb{R}^{n\times 1}\)。则前向传播过程可以向量化为如下结果
式(30)中的四个计算均用到了Python中的广播机制。例如,在计算 \(\bZ^{[1]}\) 时,\(\bX(\bW^{[1]})\trans\in\mathbb{R}^{n\times d^{[1]}}\) 以及 \((\bb^{[1]})\trans\in\mathbb{R}^{1\times d^{[1]}}\);\((\bb^{[1]})\trans + \bX(\bW^{[1]})\trans\) 应当被理解为将 \((\bb^{[1]})\trans\) 加到 \(\bX(\bW^{[1]})\trans\) 的每一行。在计算 \(\bA^{[1]}\) 时,\(\sigma(\bZ^{[1]})\) 应理解为将激活函数 \(\sigma(\cdot)\) 作用于 \(\bZ^{[1]}\) 的每一个元素。
\(\hspace{1.5em}\) 基于向量化以及Python中的广播机制的损失函数为
没有特别说明,\(\bone\) 表示一个所有元素都是1的列向量,其维度取决于乘在其前面的行向量的维度。
后向传播#
\(\hspace{1.5em}\) 为了简化记号,我们记
基于向量化以及上一节(27)的计算过程,我们可以得到如下后向传播的结果。
其中,\(\circ\) 表示矩阵之间的Hadamard乘积,即两个矩阵对应元素相乘。此外,我们针对隐藏层可选取其他的激活函数 \(\sigma(\cdot)\),故在计算 \(d\bZ^{[1]}\) 时,我们保留了隐藏层对应激活函数导数 \(\sigma'(\cdot)\) 的符号形式。我们将在下一节中,介绍几个常见的激活函数类型。
\(\hspace{1.5em}\) 当我们得到损失函数对模型参数的导数后,我们仍然用(28)对模型参数进行更新。
习题#
验证(32)中的结果。
感兴趣的同学可利用逻辑回归模型生成样本量为\(n\)的训练集,并基于
Python以及本节介绍的前向传播与后向传播结果编写全连接神经网络的训练过程。我们将在接下来的课程中,完成整个过程的代码编写。
激活函数#
\(\hspace{1.5em}\) 在前面介绍的神经网络中,函数 \(\sigma(z)=\{1+\exp(-z)\}^{-1}\) 的作用为将一个线性变换的结果进行非线性变换,进而将实数映射到(0,1);这个非线性变换在人工智能领域称为激活函数。对于深度学习众多网络模型而言,激活函数是神经网络中的“非线性引擎”,使得网络能够完成各种各样复杂的工作;因此,激活函数是网络模型中一个至关重要的组件。如果没有激活函数,无论神经网络层数有多深,结构有多复杂,其最终都将沦为一个简单的线性模型,无法捕捉和表示现实世界中的复杂数据和函数关系。通过这样的方式,激活函数为神经网络引入了非线性特性,使得网络能够学习和表示各种复杂的数据分布和函数关系。本节所讨论的关于激活函数的内容,不仅仅适用于全连接神经网络模型,也广泛适用于其他复杂的网络模型。
\(\hspace{1.5em}\) Sigmoid激活函数由于其简单性和平滑输出的特点,曾经在神经网络中被广泛使用。尽管如此,由于其梯度消失问题、非零中心输出以及饱和区域的存在,近年来在深层神经网络中逐渐被ReLU及其变种所取代。然而,在处理二分类问题和需要概率输出的特定应用中,Sigmoid函数仍然是一个有效的选择。选择合适的激活函数通常需要根据具体问题和架构进行实验和调整。
Sigmoid激活函数
- 形式为:
- \[\sigma(z) = \frac{1}{1+\exp(-z)}。\]
值域为:(0,1)。
- 导数为:
- \[\sigma'(z) = \sigma(z)\{1-\sigma(z)\}。\]
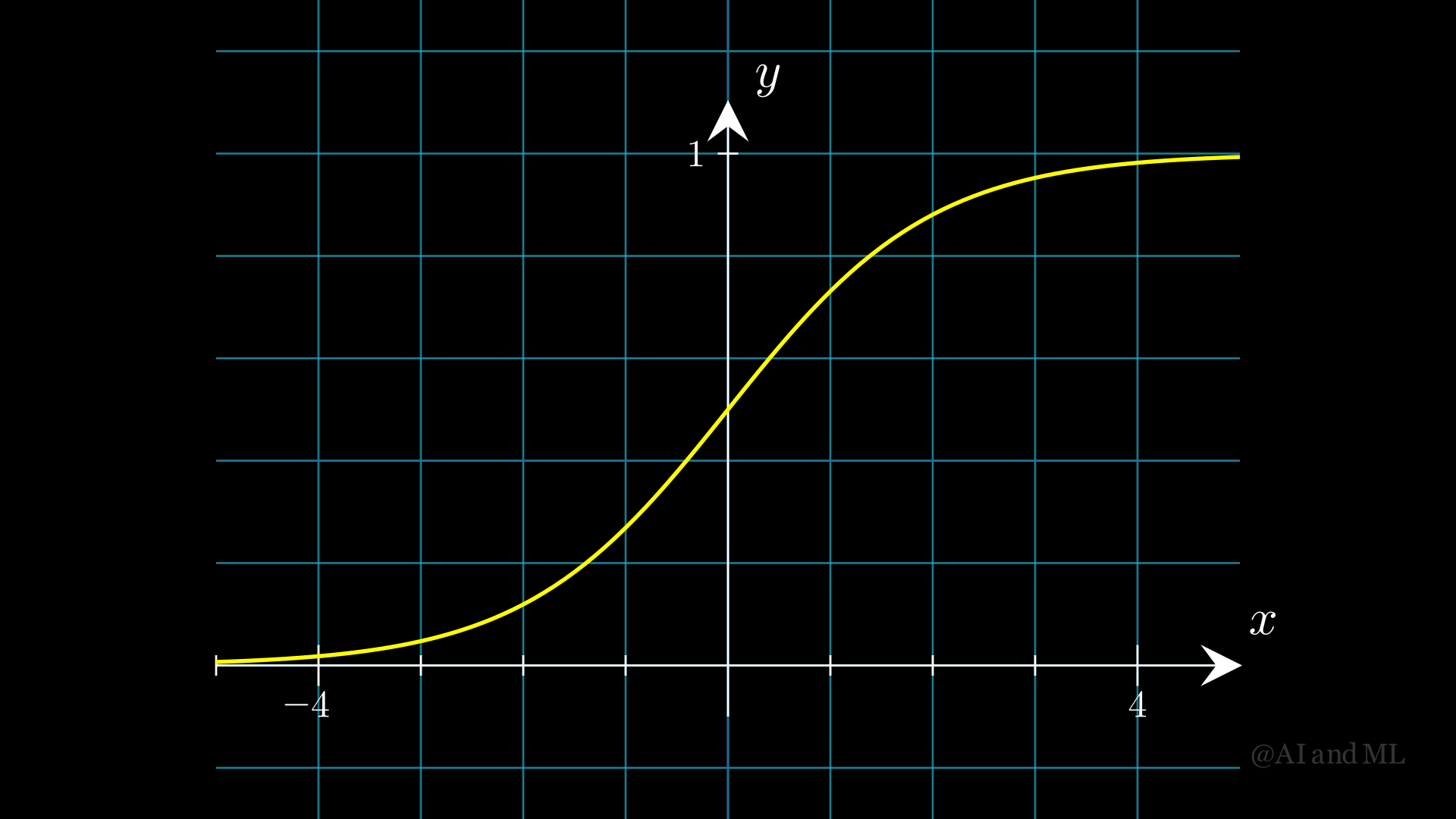
图 2 Sigmoid激活函数图像#
优点:
在二分类问题中的应用:Sigmoid函数特别适合作为输出层的激活函数,因为其输出值域为(0, 1),它可以将输出值解释为概率。
对于异常值,其对应的梯度接近于0,有助于在训练初期加速学习。
导数求解简单,即 \(\sigma'(z)= \sigma(z) \{1-\sigma(z) \}\)。
缺点:
梯度消失问题 :当输入值非常大或非常小时,Sigmoid函数的梯度接近于0,这会导致在反向传播过程中梯度消失,从而影响神经网络的训练效果。此外,其导数的范围在(0,0.25)之间,对于深层神经网络而言,梯度消失问题较为严重。例如,对于一个5层的神经网络而言,第一隐藏层所得到的梯度最多为 \(0.25^5\approx 0.001\)。
输出不是以0为中心的:Sigmoid函数的输出总是正的,这会导致在训练过程中权重更新的方向总是相同的,从而可能减慢收敛速度。换言之,后一层的神经元将得到上一层神经元非0均值的信号输出;随着层数的加深,这将改变信号的原始分布。
激活函数计算量大: 前向传播和后向传播的计算过程中涉及到幂指数和除法运算。
\(\hspace{1.5em}\) 为了克服Sigmoid函数的一些缺点,学者们提出利用Tanh函数作为激活函数。Tanh函数的值域为(-1, 1),其输出是以0为中心的,这有助于加快神经网络的收敛速度。与Sigmoid函数类似,Tanh函数也存在梯度消失的问题。当输入值很大或很小时,Tanh函数的梯度同样会趋近于0。
(双曲正切)Tanh激活函数
- 形式为:
- \[\sigma(z) = \frac{2}{1+e^{-2z}}-1。\]
值域为:(-1,1)。
- 导数为:
- \[\sigma'(z) = 1-\sigma^2(z) 。\]
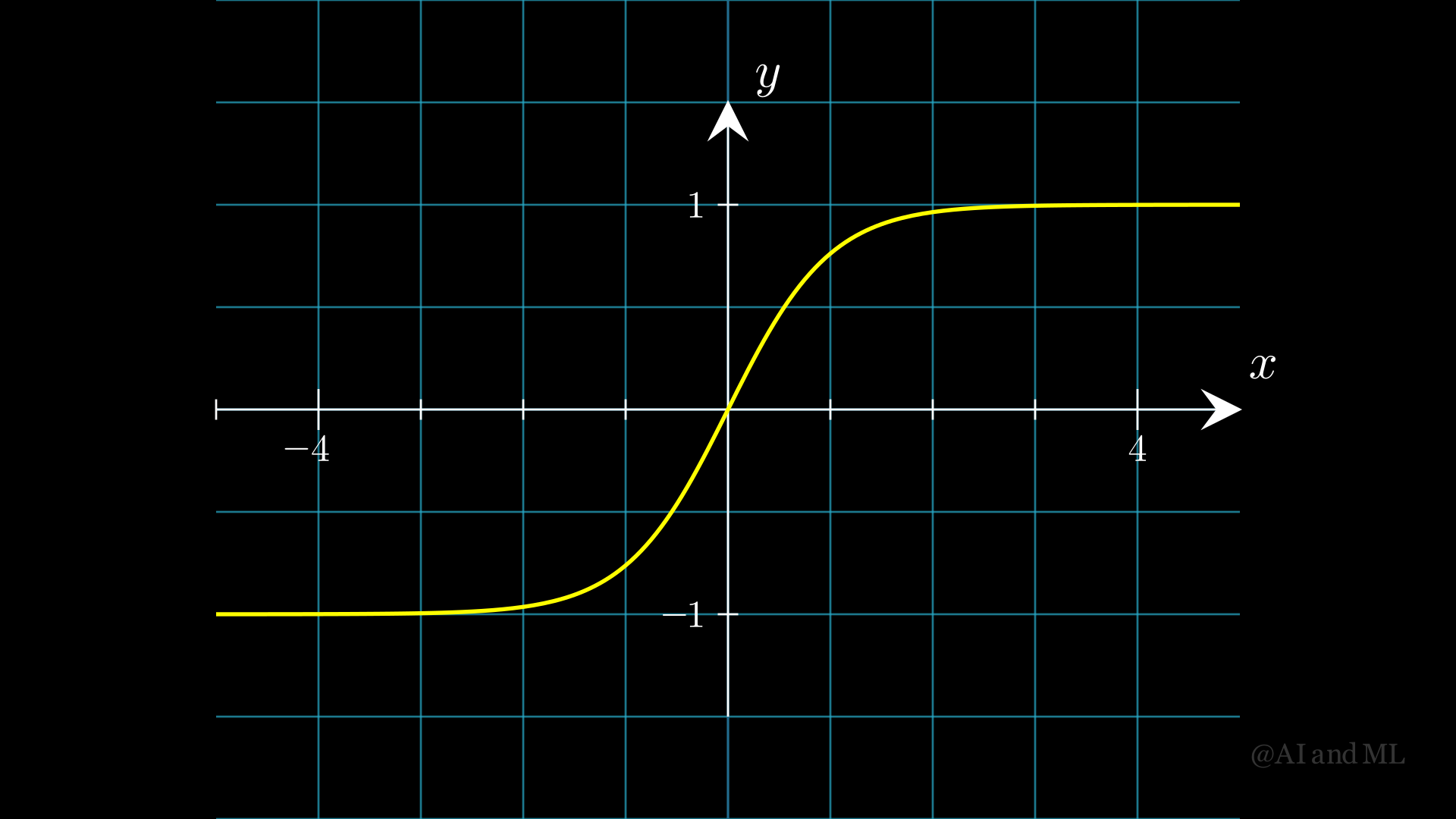
图 3 Tanh激活函数图像#
优点:
输出值中心对称:与输出值范围为(0, 1)的sigmoid函数不同,tanh函数的输出值范围是(-1, 1)。这种属性使得tanh函数的输出值以零为中心,有助于优化过程,确保激活值的均值接近零。
较宽范围内的梯度:相比于sigmoid函数,tanh函数的梯度在中间范围内更陡峭,这对于学习过程特别有利。这一特性有助于网络在训练期间更有效地学习。
对称性:tanh函数关于原点对称。这种对称性可以帮助训练过程更快收敛。
缺点:
梯度消失问题:类似于sigmoid函数,tanh函数也会遇到梯度消失问题。当输入值处于极端(非常大或非常小)时,梯度会变得非常小,从而减慢深层网络的学习速度。
激活函数计算量大: 前向传播和后向传播的计算过程中涉及到幂指数和除法运算。
不适用于稀疏激活:与下面要介绍的ReLU不同,tanh不会自然地鼓励稀疏激活(即许多激活值为零)。稀疏激活在某些类型的神经网络(如计算机视觉中使用的网络)中可能是有益的。
\(\hspace{1.5em}\) ReLU(Rectified Linear Unit)激活函数由于其计算简单、高效,并且有助于缓解梯度消失问题,成为了深度学习中广泛使用的激活函数。尽管存在Dying ReLU问题和非零中心输出等缺点,但其优点在大多数应用场景中占据主导地位。对于面临Dying ReLU问题的情况,可以考虑使用其变种如Leaky ReLU、Parametric ReLU(PReLU)或Exponential Linear Unit(ELU)来改进模型性能。选择合适的激活函数应根据具体问题和神经网络架构进行实验和调整。
ReLU(Rectified Linear Unit)激活函数
- 形式为:
- \[\sigma(z) = \max(0,z)。\]
值域为:[0, \(\infty\))。
- 导数为:
- \[\begin{split}\sigma'(z) = \begin{cases} 0 & \text{if } z \leq 0 \\ 1 & \text{if } z > 0 \end{cases}。\end{split}\]
备注
\(\hspace{1.5em}\) ReLU激活函数在 \(z=0\) 处不可导,但我们在实际中通常把这一点的“导数”定义为0。
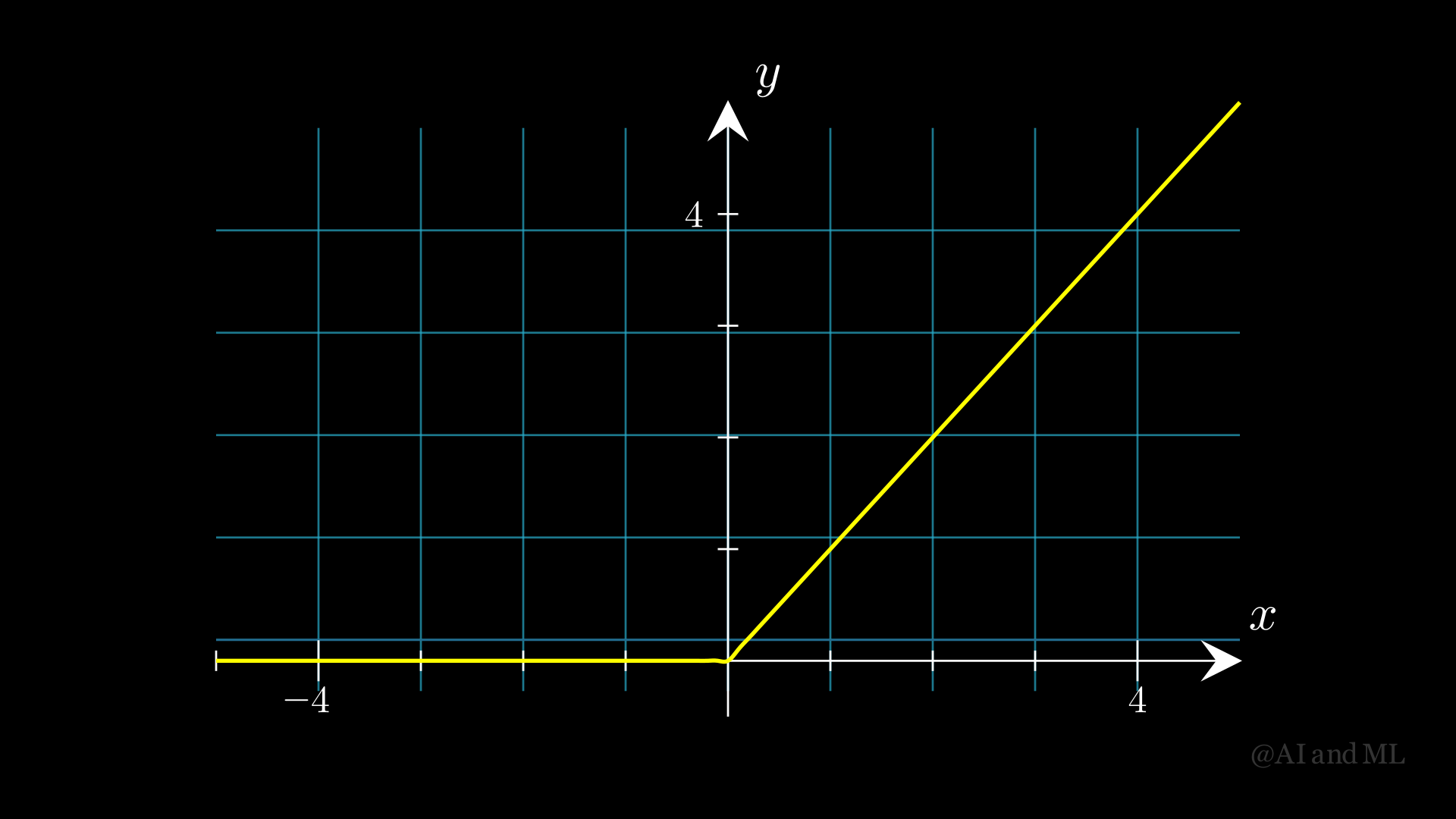
图 4 ReLU激活函数图像#
优点:
计算简单且高效:ReLU函数的计算非常简单,只需要比较输入值和零,计算效率非常高。
减轻梯度消失问题:与Sigmoid和tanh两个激活函数不同,ReLU在正区间内具有恒定的梯度,不会出现梯度消失问题。这使得网络在训练过程中可以更有效地进行梯度更新。
稀疏激活:ReLU函数会将所有负值输出为零,从而导致一部分神经元在任何给定时间不被激活。这种稀疏激活有助于提高网络的计算效率和减少过拟合。
快速收敛:使用ReLU激活函数的神经网络通常能够更快地收敛,因为在正区间内梯度不会饱和。
缺点:
Dying ReLU问题:如果一个神经元的权重在训练过程中被更新为负值,则该神经元可能永远不会被激活(输出始终为零)。这称为“Dying ReLU”问题,可能导致部分神经元在整个训练过程中失效。
不对称输出:ReLU的输出范围是[0, \(\infty\)),这意味着它不是零中心的。这可能导致训练过程中参数更新的效率降低。
不可微点:与下面要介绍的ReLU不同,在x=0处,ReLU函数不可微,但在实践中这通常不会对训练过程产生重大影响。
\(\hspace{1.5em}\) Leaky ReLU(Leaky Rectified Linear Unit)函数是对ReLU函数的一种简单改进。当输入为负时,Leaky ReLU函数不会将输出置为0,而是通过一个小的正数(如0.01)乘以输入来得到一个非零的输出。这样,即使输入为负,Leaky ReLU函数也能保证梯度不会消失。ELU函数则是另一种改进版本的ReLU函数。与Leaky ReLU函数类似,当输入为负时,ELU函数也会通过一个非线性变换来得到一个非零的输出。不同的是,ELU函数在负输入部分有一个平滑的过渡,这有助于缓解梯度消失问题,并且使得ELU函数的输出均值接近于0。我们仅仅对Leaky ReLU激活函数进行简单的介绍。
Leaky ReLU(Leaky Rectified Linear Unit)激活函数
- 形式为:
- \[\begin{split}\sigma(z) = \begin{cases}z&\mbox{如果} z>0\\ \alpha z & \mbox{如果}z\leq 0\end{cases},\end{split}\]
其中,\(\alpha>0\) 是一个预选选定的较小的值,例如 \(\alpha=0.01\)。
值域为:(\(-\infty\), \(\infty\))。
- 导数为:
- \[\begin{split}\sigma'(z) = \begin{cases} \alpha & \text{if } z \leq 0 \\ 1 & \text{if } z > 0 \end{cases}。\end{split}\]
备注
\(\hspace{1.5em}\) Leaky ReLU激活函数在 \(z=0\) 处不可导,但我们在实际中通常把这一点的“导数”定义为 \(\alpha\)。
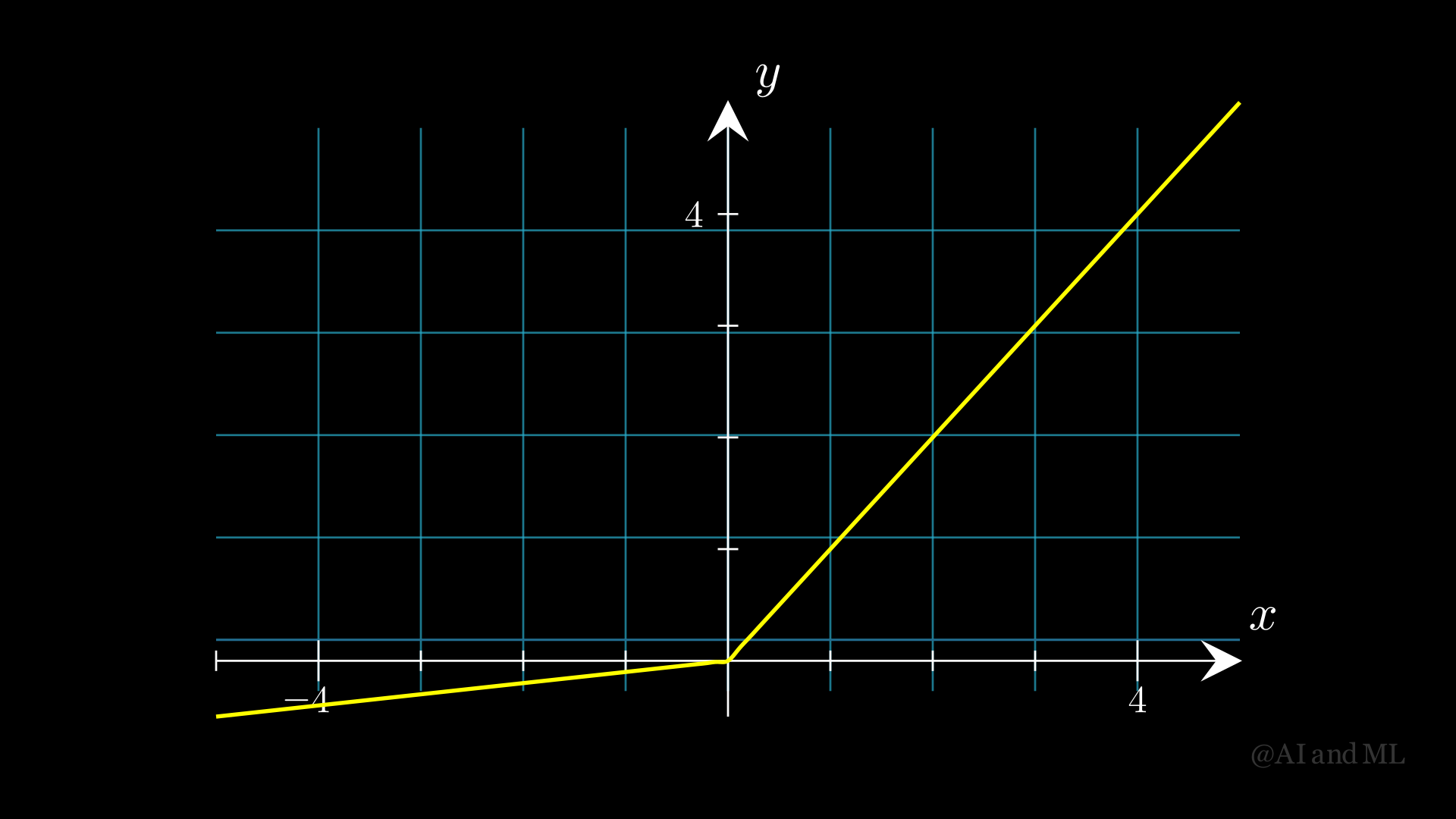
图 5 Leaky ReLU激活函数图像。其中,\(\alpha=0.1\)#
优点:
解决Dying ReLU问题:Leaky ReLU通过在输入小于或等于零时使用一个很小的斜率 \(\alpha\),使得神经元即使在输入为负时也能保持一定的激活,从而避免了Dying ReLU问题。
计算简单:与ReLU类似,Leaky ReLU的计算也非常简单,只需要比较输入值和零,然后乘以相应的斜率。
避免稀疏激活:因为Leaky ReLU在负区间内有一个小的斜率,避免了过度稀疏激活,这有助于保持模型的表达能力。
更好的梯度流动:Leaky ReLU在负区间内有非零梯度,这使得梯度能够在反向传播过程中更好地流动,从而有助于更深层神经网络的训练。
缺点:
固定参数 \(\alpha\):通常情况下,\(\alpha\) 是一个固定的小值,但选择一个合适的 \(\alpha\) 可能需要一些实验,特别是对于不同的任务和数据集。
不对称输出:尽管Leaky ReLU的输出范围是(\(-\infty\), \(\infty\)),但其并不是以0为中心的。这意味着它不是零中心的。这可能导致训练过程中参数更新的效率降低。
可能引入负值影响:尽管 \(\alpha\) 很小Leaky ReLU在负区间的输出依然是负值,这可能在某些情况下对模型性能产生负面影响。
\(\hspace{1.5em}\) Leaky ReLU激活函数通过在负区间引入一个小的斜率,解决了ReLU的Dying ReLU问题,同时保持了计算的简单性和高效性。尽管存在非零中心输出和选择合适 \(\alpha\) 值的挑战,其优点使得它在深度学习中得到了广泛应用。对于大多数应用场景,Leaky ReLU提供了一个更稳健的选择,有助于提高模型的稳定性和性能。选择合适的激活函数应根据具体问题和神经网络架构进行实验和调整。
\(\hspace{1.5em}\) 除了上述几种常见的激活函数外,还有一些其他的激活函数也被广泛应用于神经网络中。例如,Softmax函数是多分类问题中常用的输出层激活函数,它能够将神经元的输出转换为一个概率分布。Maxout函数则是一种更为通用的激活函数,它可以看作是ReLU函数和Leaky ReLU函数的推广。通过调整Maxout函数的参数,我们可以得到不同的激活函数形式,从而适应不同的应用场景。
\(\hspace{1.5em}\) 在选择激活函数时,我们需要考虑多个因素。首先,我们需要根据具体的应用场景来选择合适的激活函数。例如,在二分类问题中,我们通常选择Sigmoid函数作为输出层的激活函数;在多分类问题中,我们则选择Softmax函数。其次,我们需要考虑激活函数的梯度特性。在选择激活函数时,我们应尽量避免选择那些容易导致梯度消失或梯度爆炸的函数。最后,我们还需要考虑激活函数的计算效率和稳定性。在实际应用中,我们需要综合考虑这些因素,选择最适合的激活函数来提高神经网络的性能和稳定性。
\(\hspace{1.5em}\) 总的来说,选择激活函数是神经网络设计中的关键步骤,需要结合具体的应用场景、数据特性以及实验结果进行决策。默认情况下,ReLU及其变种是较好的起点,但在特定情况下,使用其他激活函数如Sigmoid、Tanh或Softmax可能会更合适。通过实验和验证,可以找到最适合当前任务的激活函数,从而优化神经网络的性能。
习题#
验证本节中所讨论的Sigmoid激活函数和Tanh激活函数的导数形式。
针对Sigmoid、Tanh、ReLU和Leaky ReLU等四个不同的激活函数,分别在一张图中,用两种不同颜色绘制激活函数及其对应的导数图像,并将横坐标限制在[-4,4]。
梯度下降及其衍生算法#
\(\hspace{1.5em}\) 在 (32) 中,我们主要利用批量梯度下降(Batch gradient descent)算法,即每步迭代更新参数时,我们利用训练集中所有样本信息计算梯度,并基于 (28) 对参数进行更新。批量梯度下降法的主要优势在于,在合理设置较小学习率的前提下,每次参数更新都能确保损失函数朝着全局最优方向收敛。然而,这种方法的计算开销较高,尤其当训练数据规模较大时,其效率劣势会显著放大。在深度学习模型的训练过程中,由于通常需要处理海量训练样本,批量梯度下降法因计算效率不足而变得不够实用。
\(\hspace{1.5em}\) 在本节中,我们将讨论几种衍生的梯度下降算法。需要指出的是,不同的梯度下降算法的核心在于如何计算“梯度”,而不更改参数的更新规则。对于 \(t\geq0\),批量梯度下降法更新模型参数的规则为:
其中,\(\mbox{d}\bW^{[l](t)}\) 和 \(\mbox{d}\bb^{[l](t)}\) 的计算基于全部训练集以及当前模型参数 \(\bW^{[l](t)}\) 和 \(\bb^{[l](t)}\) (\(l=1,\ldots,L\))。 本节需要给出的是,如何更有效地计算以上更新过程中的 \(\mbox{d}\bW^{[l](t)}\) 以及 \(\mbox{d}\bb^{[l](t)}\)。需要指出的是,此处的 \(\mbox{d}\bW^{[l](t)}\) 以及 \(\mbox{d}\bb^{[l](t)}\) 不应被狭隘地理解损失函数对相应模型参数的偏导数,应当理解为每步更新的方向。
\(\hspace{1.5em}\) 我们将首先介绍小批量梯度下降法,这个方法拓展了批量梯度算法,适量的小批量选择能够提高模型的训练效率。小批量梯度下降和批量梯度下降两个算法着重在于每次迭代利用多少数据计算梯度。此外,我们还将介绍Momentum、RMSprop以及Adam算法,这三个算法可得到更加稳定的 \(\mbox{d}\bW^{[l](t)}\) 以及 \(\mbox{d}\bb^{[l](t)}\),进而使模型训练过程更加高效。
小批量梯度下降法#
\(\hspace{1.5em}\) 记训练集为 \(\{(\bx_i,y_i):i=1,\ldots,n\}\)。在每步更新中,小批量梯度下降法(Mini-batch gradient descent)只用一部分训练样本计算 \(\mbox{d}\bW^{[l](t)}\) 以及 \(\mbox{d}\bb^{[l](t)}\)。具体地讲,我们首先将训练集按照每个子集包含 \(m\) 个训练样本的规模(随机) 划分 成若干小的训练集,即 \(\{(\bx_i,y_i):i=1,\ldots,n\}=S_1\cup S_2\cdots \cup S_k\),其中,\(k=\lceil n/m\rceil\),\(S_k\) 的样本规模不超过 \(m\)。需要指出的是,此时 \(S_1,\ldots,S_k\) 是两两不交的。对 \(t\geq0\),\(\mbox{d}\bW^{[l](t)}\) 和 \(\mbox{d}\bb^{[l](t)}\) 的计算仅基于 \(S_{t\%k}\) 中的样本以及当前模型参数 \(\bW^{[l](t)}\) 和 \(\bb^{[l](t)}\) (\(l=1,\ldots,L\)),其中,\(a\%b\) 是指两个正整数的取余运算。当迭代遍历了训练集中的每个样本时,我们称训练过程完成一个训练周期(Epoch)。
\(\hspace{1.5em}\) 小批量梯度下降的两个特殊情况为批量梯度下降(\(m=n\))以及随机梯度下降(\(m=1\))。
备注
\(\hspace{1.5em}\) 在实际训练神经网络模型时,划分成小批量训练子集的规模通常为 \(m=2^f\),其中 \(f\) 为某正整数。例如,\(m=256\) 或者 \(m=1024\)。训练周期(Epoch)的个数决定了模型是否对训练集过拟合或者欠拟合,其个数的选择因不同的应用而不同。
批量梯度下降和小批量梯度下降的比较
\(\hspace{1.5em}\) 批量梯度下降和小批量梯度下降是两种核心的梯度下降算法,它们各自展现出了独特的优势与局限。批量梯度下降在每次参数更新时都会利用全部训练数据,从而确保梯度方向的准确性,其使得在学习率较小的情况下,目标函数下降地更加稳定,且算法实现相对更加直观易懂。然而,其高昂的计算成本和巨大的内存占用,使得它在处理大型数据集时显得力不从心。相比之下,小批量梯度下降则通过每次仅使用一小部分数据来计算梯度,显著降低了计算成本,减少了内存占用,并提高了算法的扩展性,使其更适应大数据环境。同时,小批量梯度下降在某些情境下可能通过引入随机性来加速收敛。但是,这种方法也存在梯度方向可能受噪声影响、需要细致调整批量大小参数以及目标函数下降不稳定等潜在问题。因此,在实际应用中,选择哪种梯度下降算法需根据具体任务、数据集特性以及计算资源等因素进行综合考量,以期在算法效率、内存使用、收敛稳定性和最终模型性能之间找到最佳平衡点。总的来说,批量梯度下降则在处理小规模数据集的场合中仍然具有重要价值,而小批量梯度下降因其灵活性和高效性在深度学习领域得到了广泛应用。
\(\hspace{1.5em}\) 尽管小批量梯度下降能够提高计算效率,但有些损失函数的形式比较复杂,梯度往往不能给出高效的更新策略。例如,图 6中所展示的损失函数在一个方向变化较大,在另一个方向变化缓慢。如果初始值以及学习率选择得不好,则梯度下降算法的更新结果将非常不稳定,甚至发散。
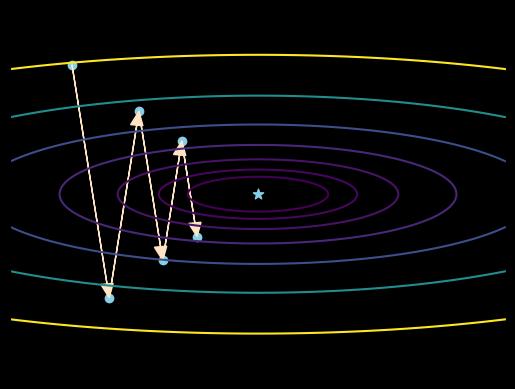
图 6 低效的更新策略。图中曲线表示了一个二元目标函数等高线,其中横纵坐标分别代表不同的模型参数,中心五角星位置为局部极小值,箭头和实心圆点表示每次迭代更新后的参数值。#
\(\hspace{1.5em}\) 下面介绍的三个计算梯度更新方向的策略,其均能够在一定程度上减轻图 6所遇到的问题。
Momentum#
\(\hspace{1.5em}\) 我们仔细观察图 6中参数的更新过程可知,我们希望“减小”上下方向的更新幅度,而“增加”左右方向的更新幅度。如果我们将每步的更新方向看成一个序列,相邻两步的更新方向的“上下”方向符号相反,而“左右”方向的符号相同。因此,我们在第 \(t\) 步更新时,如果能够将当前更新方向和前面所有更新方向取均值,并将该均值方向作为参数的更新方向,那么我们很有可能得到一个更优的更新策略。
\(\hspace{1.5em}\) 然而,存储每步更新方向对存储需求巨大,尤其是当我们训练的深度神经网络模型具有海量参数时。在本节中,我们考虑另外一种“平均”方法,即“指数加权移动平均”(Exponential weighted moving average)。记 \(\{\bd_i:i=1,2,\ldots\}\) 为某序列,记 \(\{\bv_i:i=0,1,\ldots\}\) 为其对应的指数加权移动平均值,则该加权平均值的计算公式如下:
其中,\(\beta_1\) 为算法的“遗忘系数”,\(\bv_0\) 为该滑动平均初始值。学者们通常也称 \(\{\bv_i:i=0,1,\ldots\}\) 为动量(Momentum)项。初始值 \(\bv_0\) 可以根据不同应用进行设置,我们通常令 \(\bv_0=0\)。需要指出的是,\(\beta_1\) 的大小决定了指数加权移动平均值 \(\bv_i\) 对当前结果 \(\bd_i\) 的遗忘程度;\(\beta_1\) 的值越大,\(\bd_i\) 对 \(\bv_i\) 的贡献越小。在实际计算时,我们通常令 \(\beta_1=0.9\)。该参数为模型的超参数(即不可通过梯度进行迭代更新求解的模型参数),但我们通常不对 \(\beta_1\) 进行调参。关于超参数的讨论,请参见 偏差-方差分析 一节。
简单的数学推导
\(\hspace{1.5em}\) 当 \(\beta_1\in(0,1)\) 时,我们有如下结果
即
记 \(\bv_0=0\),我们有如下结果
\(\hspace{1.5em}\) 由 (33) 可知,当 \(n\) 很大时,\(\bv_n\) 可近似看成 \(\{\bd_i:i=1,\ldots,n\}\) 的加权平均。加权权重呈指数衰减,故距离 \(n\) 较远的“观测” \(\bd_i\) 对 \(\bv_n\) 的贡献是忽略不计的。通常,我们可认为 \((1-\beta_1)^{-1}\) 为计算指数加权移动平均时,权重不可忽略的序列的个数。即 \(\beta_1\) 值越大,序列中的每个结果 \(\bv_n\) “记住”的序列就越长。
\(\hspace{1.5em}\) Momentum利用指数加权移动平均计算已有更新方向的“均值”方向,并基于此均值方向对参数进行更新,其过程如下:
其中,\(l=1,\ldots,L\),\(\bv_W^{[l](t+1)} = \beta_1 \bv_W^{[l](t)} + (1-\beta_1)\mbox{d}\bW^{[l](t)}\),\(\mbox{d}\bW^{[l](t)}\) 为损失函数对模型参数 \(\bW^{[l]}\) 的偏导数在当前参数取值 \(\btheta^{(t)}\) 下的函数值;\(\bv_b^{[l](t)}\) 的计算类似。
\(\hspace{1.5em}\) 图 7对比了批量梯度下降和Momentum对参数的更新结果。可见,Momentum的更新更加稳健高效。
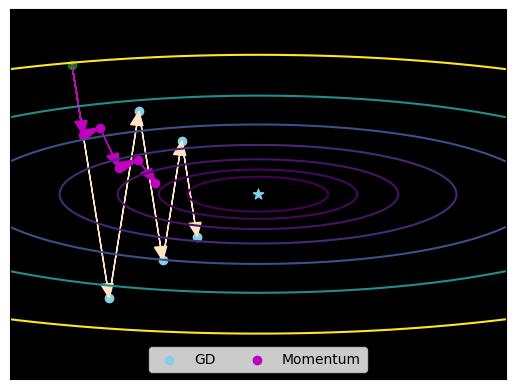
图 7 梯度下降以及Momentum参数更新路径。#
\(\hspace{1.5em}\) 总之,Momentum算法通过引入动量(Momentum)的概念,使得参数更新不仅依赖于当前的梯度,还考虑了之前梯度的累计效果。具体来说,它记录了之前梯度的指数加权平均值,作为当前更新的方向,从而平滑了梯度下降的路径,减少了震荡,并有可能帮助算法跳出局部极小值,找到更优的全局最小值。
RMSprop#
\(\hspace{1.5em}\) Momentum算法尽管能够较为有效地平滑梯度下降的路径,但其在参数各分量上利用相同的学习率会造成参数更新效率的降低。通过图 6展示的问题,我们希望不同参数具有不同的学习率,即我们希望上下方向的学习率稍微低一些,而左右方向的学习率稍微高一些。这样,我们能够得到效率更高的参数更新算法。
\(\hspace{1.5em}\) 为了符号简洁,我们用 \(\bb\) 代表某一层偏置向量,用 \(\bW\) 代表某一层权重矩阵;即我们在本节中不区分层数。RMSprop算法的更新过程为:
初始化 \(\bs_b^{(0)}=0\) 以及 \(\bs_W^{(0)}=0\),其中 \(\bs_b^{(0)}\) 的维度与 \(\bb\) 相同,\(\bs_W^{(0)}\) 的维度与 \(\bW\) 相同。
基于第 \(t\) 步的模型参数,计算损失函数对参数的梯度,即 \(\mbox{d}\bb^{(t)}\) 以及 \(\mbox{d}\bW^{(t)}\)。
更新
其中,“\(\circ\)”为Hadamard乘积。
更新模型参数
其中,乘法和除法均表示元素乘除。
回到第2步直至收敛。
\(\hspace{1.5em}\) 对于RMSprop算法,我们通常令 \(\beta_2=0.99\) 和 \(\epsilon=10^{-8}\)。这两个超参数我们一般不做更改。图 8对比了批量梯度下降、Momentum以及RMSprop对参数的更新结果。可见,RMSprop算法参数更新路径更为平滑,且收敛到真值的速度更快一些。
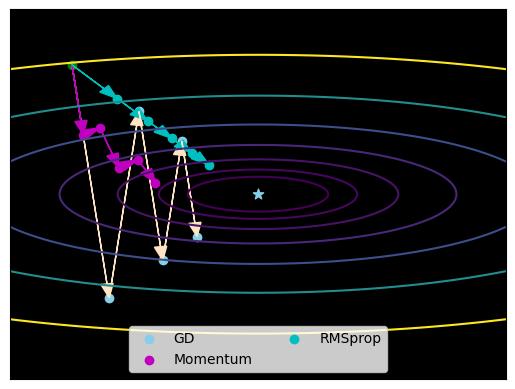
图 8 梯度下降、Momentum以及RMSprop参数更新路径。#
\(\hspace{1.5em}\) 总之,RMSprop算法是一种基于自适应学习率的优化算法,通过计算历史梯度的指数加权移动平均来自适应地调节每个模型参数的学习率。该算法具有自适应学习率、解决学习率过大或过小问题以及较好的收敛性和性能等优点,但也存在超参数依赖和可能不适合所有问题等缺点。在实际应用中,需要根据具体任务和数据集的特点来选择合适的优化算法和参数设置。
Adam#
\(\hspace{1.5em}\) Adam(Adaptive Moment Estimation)算法是一种自适应学习率的优化算法,广泛用于深度学习中神经网络的训练。Adam算法结合了动量梯度下降法(Momentum)和RMSProp算法的优点,通过计算梯度的一阶矩估计和二阶矩估计(即梯度的平方的移动平均值),为不同的参数设计独立的自适应学习率。这种自适应调整使得Adam算法能够在训练过程中动态地调整学习率,从而加速模型的收敛并提高训练效果。
\(\hspace{1.5em}\) Adam算法能够根据不同参数的梯度特性自适应地调整学习率。对于梯度较大的参数,学习率会相应减小,以避免参数更新过快导致震荡;对于梯度较小的参数,学习率会相应增大,以加速收敛。该算法使用二阶矩估计来调整学习率,使其能够更好地适应参数的变化。这有助于算法在复杂和非稳态问题上表现出更好的性能。此外,由于初始阶段一阶矩估计和二阶矩估计的值都比较小,为了消除偏差,Adam算法进行了偏差修正。这有助于算法在初始阶段也能保持稳定的性能。最后,Adam算法的计算效率高,所需内存少,适合解决含大规模数据和参数的优化问题。
\(\hspace{1.5em}\) 为了符号简洁,我们仍然用 \(\bb\) 代表某一层偏置向量,用 \(\bW\) 代表某一层权重矩阵;即我们在本节中不区分层数。Adam算法的更新过程为:
初始化 \(\bv_b=0\),\(\bv_W=0\),\(\bs_b^{(0)}=0\) 以及 \(\bs_W^{(0)}=0\),其中 \(\bv_b\) 和 \(\bs_b^{(0)}\) 的维度与 \(\bb\) 相同,\(\bv_W\) 和 \(\bs_W^{(0)}\) 的维度与 \(\bW\) 相同。
基于第 \(t\) 步的模型参数,计算损失函数对参数的梯度,即 \(\mbox{d}\bb^{(t)}\) 以及 \(\mbox{d}\bW^{(t)}\)。
更新
更新模型参数
其中,乘法和除法均表示元素乘除。
回到第2步直至收敛。
\(\hspace{1.5em}\) 对于Adam算法,我们通常令 \(\beta_1=0.9\),\(\beta_2=0.99\) 和 \(\epsilon=10^{-8}\)。图 9对比了批量梯度下降、Momentum、RMSprop和Adam算法对参数的更新结果。可见,Adam算法参数更新路径更为平滑,且收敛到真值的速度最快。
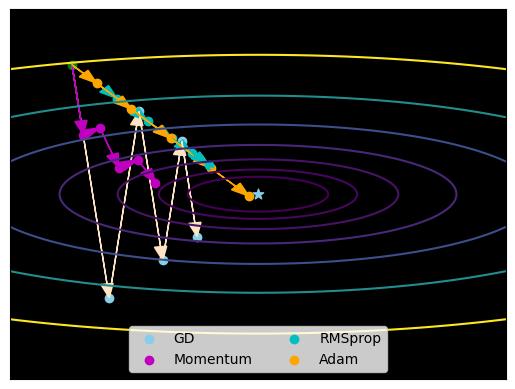
图 9 梯度下降、Momentum、RMSprop以及Adam参数更新路径。#
\(\hspace{1.5em}\) 总之,Adam算法结合了动量和自适应学习率的优点,能够加速模型的收敛速度。该算法对超参数的选择相对不敏感,能够在不同的学习率和梯度条件下自动调整步长,提高训练的稳健性。此外,该算法的实现相对简单,只需要设定几个超参数即可,不需要复杂的调参过程。
习题#
完成对梯度下降衍生算法,包括动量法、RMSprop以及Adam的函数编写。
记\(\btheta = (\theta_1,\theta_2)\trans\),考虑如下损失函数
利用梯度下降法、动量法、RMSprop以及Adam四种方法最小化以上损失函数。设置初始值为\((-10,10)\),学习率为\(\alpha=0.1\)。参考图 9,绘制10步参数更新的结果。
多隐藏层神经网络#
\(\hspace{1.5em}\) 我们已经对具有一个隐藏层的神经网络的结构以及基于向量化的训练过程有了较为清晰的了解。在本节中,我们将讨论更为一般的、具有多个隐藏层的全连接神经网络及其训练过程。例如,图 10展示了用来分析二分类问题的、具有两个隐藏层的神经网络模型,其中 \(\bx\) 为某特征向量。在该网络中,第一(隐藏)层具有 \(d^{[1]}=6\) 个神经元,第二(隐藏)层具有 \(d^{[2]}=4\) 个神经元,第三层为输出层,具有 \(d^{[3]}=1\) 个神经元。对于多分类问题,输出层的神经元个数往往与类别数量相等;我们将在 Softmax回归模型 一节中对这个问题进行讨论。
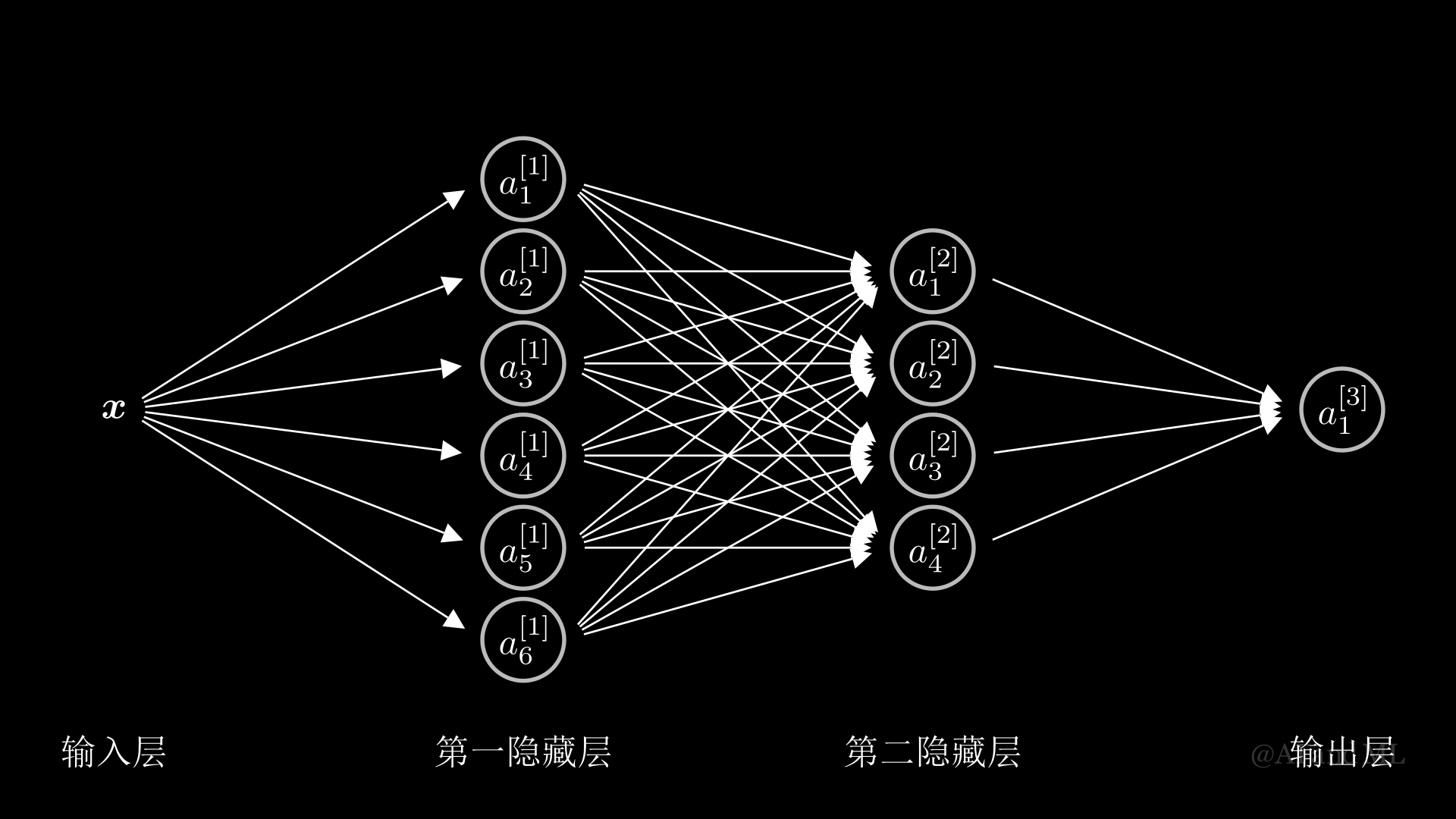
图 10 具有两个隐藏层的全连接神经网络#
前向传播#
\(\hspace{1.5em}\) 在本节中,我们假设神经网络共有 \(L\) 层,其中第 \(L\) 层为输出层。我们遵循上一节中的向量化过程以及基于Python的广播机制。记 \(\bA^{[0]}=\bX\),则对于 \(l\geq1\),前向传播的计算过程如下:
其中,\(\bb^{[l]}\) 和 \(\bW^{[l]}\) 对应于第 \(l\) 层的偏置项和权重项,\(\sigma^{[l]}(z)\) 为第 \(l\) 层的激活函数,\(\sigma^{[l]}(\bZ^{[l]})\) 表示将激活函数作用于矩阵 \(\bZ^{[l]}\) 的每一个元素。
后向传播#
\(\hspace{1.5em}\) 正如我们对 (27)的讨论,为了进行后向传播,我们仅仅需要缓存前向传播中激活后的函数值,即 \(\bA^{[1]}\)、\(\bA^{[2]}\) 以及 \(\bA^{[3]}\)。
\(\hspace{1.5em}\) 首先,利用输出层结果 \(\bA^{[3]}\) 与损失函数 \(\mathcal{J}(\btheta)\) 之间的关系,我们可以得到 \(\mbox{d}\bA^{[3]}\)6不同问题对应的损失函数往往不同。例如,分类问题一般对应交叉熵损失,而一般回归问题对应于 \(l_2\) 损失。因此,损失函数对输出层的偏导数依据具体问题而定。。当 \(l=3,2\) 时,给定 \(\mbox{d}\bA^{[l]}\),我们依据如下规则计算后向传播,并得到 \(\mbox{d}\bA^{[l-1]}\):
\(\hspace{1.5em}\) 我们在处理实际问题时,相比较于层数较少但每层具有较多神经元的模型而言,我们更加倾向于选择层数较深但每层神经元较少的模型。
习题#
验证(34)中的结果。
评价二分类模型#
\(\hspace{1.5em}\) 在本章中,我们已经针对二分类问题探讨了不同的神经网络模型。在这些模型中,我们时针对给定的特征 \(\bx\),对标签 \(y\) 属于类别1的条件概率 \(P(Y=1\mid \bx)\) 进行建模,其中 \(Y\) 对应于观测标签 \(y\) 的随机变量。在实际问题中,我们可能更希望模型直接预测标签值,而不是标签属于类别1的概率值。基于预测的概率值,我们可以通过设定某个阈值 \(\tau\) 来预测标签值。例如,假设对于特征 \(\bx\) 的标签条件概率值的预测是0.7。那么,当阈值 \(\tau=0.5\) 时,由于 \(0.7>\tau\),我们将该特征对应的标签预测为1。但当阈值 \(\tau=0.8\) 时,由于 \(0.7<\tau\),我们将该特征对应的标签预测为0。需要指出的是,针对同一组概率预测值,不同的阈值对应着不同的标签预测。接下来,我们将介绍如何基于预测的标签值,衡量一个二分类模型的优劣。在下面的分析中,我们称类别0为负类,类别1为正类。
混淆矩阵#
\(\hspace{1.5em}\) 为了评估二分类模型的性能,我们通常使用混淆矩阵(Confusion Matrix)及其衍生指标。
混淆矩阵
\(\hspace{1.5em}\) 混淆矩阵是一种用于评估分类模型性能的工具,它展示了实际类别与模型预测类别之间的关系。在二分类问题中,混淆矩阵通常是一个2x2的表格,包含以下四个部分:
真正类(True Positive, \(\cotp\)):模型正确地预测为正类的样本数。
假正类(False Positive, \(\cofp\)):模型错误地预测为正类的样本数(实际上是负类)。
真负类(True Negative, \(\cotn\)):模型正确地预测为负类的样本数。
假负类(False Negative, \(\cofn\)):模型错误地预测为负类的样本数(实际上是正类)。
\(\hspace{1.5em}\) 一个好的模型能够使真正类和真负类的个数尽可能多。下图归纳了混淆矩阵的四个部分:
\(\hspace{1.5em}\) 混淆矩阵不仅提供了分类结果的直观展示,还允许我们计算各种性能指标,如准确率(Accuracy)、精确率(Precision)、召回率(Recall)或真正率(True Positive Rate, TPR)、假正率(False Positive Rate, FPR)以及F1分数等。这些指标帮助我们更全面地了解模型的性能,并指导我们进行模型选择和调优。在介绍相关概念前,我们首先考虑如下例子。
例子
\(\hspace{1.5em}\) 测试集有100个实例,其中包含60个正类,40个负类。基于某模型预测结果,我们得到:
50个真正例(\(\cotp\))
30个真负例(\(\cotn\))
10个假正例(\(\cofp\))
10个假负例(\(\cofn\))
\(\hspace{1.5em}\) 基于此,我们得到如下混淆矩阵:
准确率
\(\hspace{1.5em}\) 准确率(Accuracy)是用于评估二分类模型性能的基本指标之一。它衡量正确预测实例(正类和负类)在总实例中的比例。然而,单独使用准确率可能会产生误导。例如,在不平衡数据集上,准确率可能不是一个好的指标,因为它可能无法准确反映模型对少数类的预测性能。在这种情况下,我们可以考虑使用其他指标,如精确率、召回率或F1分数等。
- \(\hspace{1.5em}\) 计算公式为:
- \[\begin{split}\begin{eqnarray} \text{Accuracy} &=& \frac{\text{正确预测标签的数量}}{\text{总样本量}}\\ &=& \frac{\cotp + \cotn}{\cotp + \cotn+ \cofp+\cofn}。 \end{eqnarray}\end{split}\]
- \(\hspace{1.5em}\) 基于上面的例子,我们可以计算模型的准确率:
- \[\begin{split}\begin{eqnarray} \text{Accuracy} &=& \frac{\numcotp + \numcotn}{\numcotp + \numcotn+ \numcofp+\numcofn}\\ &=& \frac{4}{5}。 \end{eqnarray}\end{split}\]
精确率
\(\hspace{1.5em}\) 精确率(Precision)是用于评估二分类模型性能的关键指标之一。精确率主要关注模型预测为正类的样本中,实际为正类的比例,因此它直接反映了模型预测的准确性。精确率和召回率(参见下面定义)是相互制约的指标。召回率关注在所有实际为正类的样本中,模型成功预测出多少比例的正类样本,即查全率。在某些情况下,提高精确率可能会牺牲召回率,反之亦然。
- \(\hspace{1.5em}\) 计算公式为:
- \[\begin{split}\begin{eqnarray} \text{Precision} &=& \frac{\text{正确预测的正类的样本量}}{\text{预测为的正类的样本量}}\\ &=&\frac{\cotp}{\cotp+\cofp}。 \end{eqnarray}\end{split}\]
- \(\hspace{1.5em}\) 基于上面的例子,我们可以计算模型的准确率:
- \[\begin{split}\begin{eqnarray} \text{Precision} &=& \frac{\numcotp}{\numcotp + \numcofp}\\ &=& \frac{5}{6}。 \end{eqnarray}\end{split}\]
召回率或真正率
\(\hspace{1.5em}\) 召回率(Recall or True Positive Rate, TPR),也称为敏感性或真正类率,是评估二分类模型性能的关键指标之一。它衡量模型在数据集中识别所有相关实例(即所有实际正类实例)的能力。在错过正类实例(假负类)代价高或关键的情况下,召回率尤为重要。召回率直接反映了模型在所有实际正类样本中找出正类样本的能力。在信息检索、推荐系统、医学诊断等领域,高召回率意味着模型能够尽可能多地找出所有相关的正类样本,减少漏检。
- \(\hspace{1.5em}\) 计算公式为:
- \[\begin{split}\begin{eqnarray} \text{Recall (TPR)} &=& \frac{\text{正确预测为正类的样本数}}{\text{正确预测为正类的样本数} + \text{错误预测为负类的样本数(实际为正类)}}\\ &=&\frac{\cotp}{\cotp+\cofn}。 \end{eqnarray}\end{split}\]
- \(\hspace{1.5em}\) 基于上面的例子,我们可以计算模型的准确率:
- \[\begin{split}\begin{eqnarray} \text{Recall (TPR)} &=& \frac{\numcotp}{\numcotp + \numcofn}\\ &=& \frac{5}{6}。 \end{eqnarray}\end{split}\]
假正率
\(\hspace{1.5em}\) 假正率(False Positive Rate,FPR),也称为虚报率或第一类错误率,是用于评估二分类模型性能的指标之一。它衡量被错误分类为正类的负类实例的比例。假正率直接反映了模型将负类样本误报为正类的程度。在医学诊断、安全检测等领域,低假正率意味着模型能够更准确地识别出非目标类别,减少误报带来的不必要的干扰或成本。在假正类具有重大后果的场景中,假正率尤为重要。在ROC曲线(参见下面定义)中,假正率作为横轴,与作为纵轴的真正率(True Positive Rate,TPR)共同描述了分类器在不同阈值下的性能表现。ROC曲线下的面积(AUC)是衡量分类器整体性能的一个综合指标。
- \(\hspace{1.5em}\) 计算公式为:
- \[\begin{split}\begin{eqnarray} \text{FPR} &=& \frac{\text{错误预测为正类的样本数(实际为负类)}}{\text{错误预测为正类的样本数(实际为负类)} + \text{正确预测为负类的样本数}}\\ &=&\frac{\cofp}{\cofp+\cotn}。 \end{eqnarray}\end{split}\]
- \(\hspace{1.5em}\) 基于上面的例子,我们可以计算模型的准确率:
- \[\begin{split}\begin{eqnarray} \text{FPR} &=& \frac{\numcofp}{\numcofp + \numcotn}\\ &=& \frac{1}{4}。 \end{eqnarray}\end{split}\]
F1分数
\(\hspace{1.5em}\) F1分数是用于评估二分类模型性能的指标之一。它是精确率和召回率的调和平均数,在两者之间提供了平衡。F1分数在需要一个单一指标来评估模型性能的情况下很有用,特别是在类别不平衡的情况下。F1分数通过综合考虑精确率和召回率两个指标,能够更全面地评估模型的性能。在单一指标无法全面反映模型性能的情况下,F1分数提供了一个更为平衡的视角。F1分数对于精确率和召回率的变化都比较敏感,因此能够较为准确地反映模型在不同方面的表现。当精确率和召回率都较高时,F1分数也会相应较高;而当两者之一较低时,F1分数则会受到较大影响。
- \(\hspace{1.5em}\) 计算公式为:
- \[\begin{split}\begin{eqnarray} \text{F1分数} &=& 2 \times \frac{\text{Precision} \times \text{Recall}}{\text{Precision} + \text{Recall}}\\ \end{eqnarray}\end{split}\]
- \(\hspace{1.5em}\) 基于上面的例子,我们可以计算模型的准确率:
- \[\begin{split}\begin{eqnarray} \text{F1分数} &=& 2\times\frac{5/6\times 5/6}{5/6+5/6}\\ &=& \frac{5}{6}。 \end{eqnarray}\end{split}\]
ROC曲线#
\(\hspace{1.5em}\) ROC曲线(Receiver Operating Characteristic Curve)是用于评估二分类模型性能的图形表示7关于ROC曲线更加详细的介绍,请参见 Fawcett (2006). An introduction to ROC analysis, Pattern Recognition Letters, 27, 861-874.,其是基于 测试集 进行绘制。也就是说,我们通过训练集得到一个分类模型,再将其应用到一个测试集上,基于预测结果绘制该曲线。针对于预测条件概率的模型,它在不同阈值设置下绘制对应的召回率 (TPR) 与假正率 (FPR)。ROC曲线有助于理解不同阈值下的敏感性(即召回率)与特异性(即 1 - FPR)之间的权衡。ROC曲线下面积 (AUC) 是总结分类器总体性能的单一标量值。AUC 范围从0到1,值越高表示性能越好。
\(\hspace{1.5em}\) ROC 曲线是一个在单位正方形内的二维曲线,纵轴对应于TPR,横轴对应于FPR,该曲线用于展示这两者之间的相对关系。对于直接预测标签的模型,即仅预测正类或者负类,其预测结果仅仅对应于ROC平面上的一个点。图 11总结了六个不同分类模型的表现。
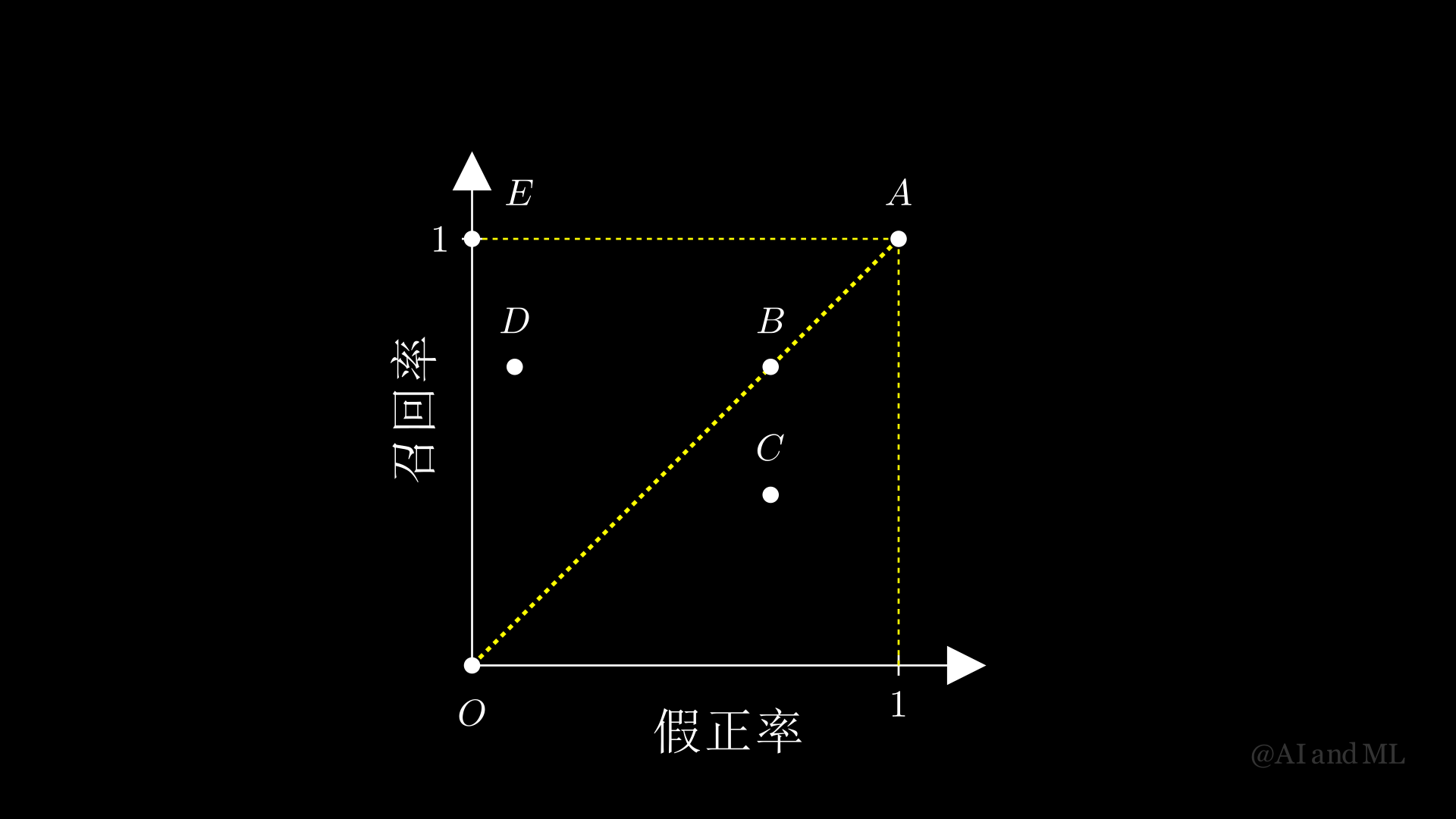
图 11 ROC曲线示意图#
\(\hspace{1.5em}\) 我们将基于图 11展示的结果,对ROC曲线进行简要介绍。
不同模型的比较
点 \(O (0,0)\):该分类模型简单地将所有样本分类为负类。因此,其TPR以及FPR均为0。如果某分类模型对应的点位于ROC平面的左下角,即原点 \(O (0,0)\) 附近,则该分类模型较保守。即只有当我们有充分的证据时,分类模型才会将其判定为正类。当总体总的正类非常少时,该分类模型的准确率较高。但错误地将正类分为负类,在某些社会问题中将造成极其严重的后果。例如,在重大传染病初期或者对于具有重要社会影响的传染病的检测等。
点 \(A (1,1)\):该分类模型简单地将所有样本分为正类。因此,其TPR以及FPR均为1。该分类模型是点 \(O\) 对应分类模型的另一个极端。如果某分类模型对应的点位于ROC平面的右上角,即点 \(O (1,1)\) 附近,则该分类模型较激进。即只要有微弱的证据,分类模型就会将其判定为正类。对于极端不平衡样本而言,这个分类模型对应的准确率仍然很高。但其错误地将负类归为正类,可通俗地认为是“宁可错杀一千,不可放过一个”。这种分类模型在应对大型传染病时,往往造成资源的大量消耗。
点 \(B (0.7,0.7)\):该点位于45°对角线上。对于ROC平面而言,位于对角线上的点往往对应于简单的随机猜测。换言之,任何在对角线上的分类模型是没有利用数据信息的。例如,点 \(B\) 的坐标为 (0.7, 0.7),对应的分类模型为随机地将任何一个样本点以0.7的概率划分为正类。
点 \(C (0.7,0.4)\):对比点 \(B\),我们可以知道,对应于点 \(C\) 的分类模型,其假正率与对应于点 \(B\) 的分类模型(随机猜测)相同,但其召回率却相对较低。也就是说,对应于点 \(C\) 的分类模型的表现不如随机猜测。由于点 \(C\) 不位于对角线上,该分类模型是利用了数据内部信息,只不过用得不太对。如果我们将该模型的预测标签进行翻转,就可以得到一个比较好的分类模型了。
点 \(D (0.1, 0.7)\):该点位于对角线上侧,相对应于对角线上的点而言,该分类模型在相同假正率的前提下具有更高的召回率。因此,该模型正确利用了数据中的信息。
点 \(E (0, 1)\):对应于该分类模型,其假正率为0,而召回率为1。也就是说,分类模型将所有正类判定为正类,而将所有负类判定为负类。这是我们理想的分类模型。
针对于一个对标签进行预测的模型,我们希望其结果尽可接近于点 \(E\)。
\(\hspace{1.5em}\) 图 11 所展示的几个点对应的是几个直接预测样本类别的分类模型。在分析实际问题时,有些模型往往预测每个样本点对应的“分数”(例如条件概率值),然后基于一个阈值进行分类。例如,在逻辑回归模型中,我们首先估计对应于特征 \(\bx\) 的标签属于正类的条件概率,然后基于阈值(例如0.5)再对样本的标签进行预测。再例如在分类树中,我们计算特征 \(\bx\) 所在最终叶节点正类的比例,然后在基于某个阈值对所对应的标签进行预测。
\(\hspace{1.5em}\) 当我们对测试集中每个样本的“得分”进行估计后,对应于不同的阈值,我们可以得到不同的分类结果,其进一步对应于ROC平面中的不同的点。当我们从大到小变动这个阈值时,我们便可在ROC平面中得到一条连接圆点和 \((1,1)\) 点的“曲线”,这个曲线往往称为ROC曲线。
\(\hspace{1.5em}\) 首先,我们介绍ROC曲线的绘制方法。假设我们观测到测试集中的真实标签,也有来自于某二分类模型对于每个样本标签的“得分”估计。
ROC曲线的绘制
将测试集按照“得分”降序排列。
将阈值 \(\tau\) 从 \(\infty\) 逐渐变化为 \(-\infty\):
2.1. 对于对应于特定阈值 \(\tau\),将“得分”大于 \(\tau\) 的样本预测为正类,否则为负类。
2.2. 基于以上分类模型,计算召回率和假正率,并标记在ROC平面上。
备注
\(\hspace{1.5em}\) 尽管在第二步中,我们需要令阈值在整个实数上变动,但实际上我们只需要考虑有限几个(只比测试集样本点个数多1个)点即可。当我们绘制ROC曲线时,我们只需从原点出发“向上走”或者“向右走”即可。随着阈值的降低,当分类模型正确预测某标签时,我们“向上走”,否则“向右走”,对应的步长取决于测试集真实正类或者负类的数量。
样本编号 |
真实标签 |
估计得分 |
|---|---|---|
1 |
1 |
0.9 |
2 |
1 |
0.8 |
3 |
0 |
0.7 |
4 |
1 |
0.6 |
5 |
1 |
0.55 |
6 |
1 |
0.54 |
7 |
0 |
0.53 |
8 |
0 |
0.52 |
9 |
1 |
0.51 |
10 |
0 |
0.505 |
\(\hspace{1.5em}\) 在上例中,正类共有6个,负类共有4个。因此,“向上走”的步长为1/6,“向右走”的步长为1/4。我们通过上面这个例子展示ROC曲线的绘制。
\(\hspace{1.5em}\) 通过上面的分析,我们可知ROC曲线越向左上方倾斜,对应的分类模型表现就越好。可见,ROC曲线与 \(x\) 轴围成的面积可以用来衡量分类模型的好坏。这个面积通常称为AUC(Area Under the Curve)。例如,随机猜测分类模型对应的AUC为0.5,上例中对应分类模型的AUC为
\(\hspace{1.5em}\) 通过以上计算可见,在开始“向右走”之前,“向上走”的越高,分类模型对应的AUC值就越大。极端情况为“向上走”到点 (0,1) 处,然后“向右走”到 (1,1) 点。此时,这个分类模型的AUC值为1。反之,若先“向右走”到 (1,0) 点,然后再“向上走”到 (1,1) 点。该分类模型对应的AUC值为0,但该分类模型也是充分利用了数据信息,只不过完全将正负类搞反了。
AUC与准确率
\(\hspace{1.5em}\) AUC衡量的是分类模型能否将正类样本的得分估计地都比负类样本高,即当我们将测试集样本按照估计得分做降序排列时,正类样本能否都排在负类样本前面。如果能达到该效果,则这个分类模型对应的AUC值为1。对应于估计得分的分类模型而言,而准确性是依赖于阈值的,不同阈值往往对应于不同的准确性。也就是说,我们可能得到一个分类结果,其对应的AUC值为1,但准确率低于1。然而,对于AUC为1的分类模型,(理论上讲)我们总能找到一个阈值,使得分类的准确率为1。
习题#
基于以下真实标签和预测标签,计算预测的准确率、精确率、召回率、假正率以及F1分数。
1 y_true = np.array([1,1,0,1,1,1,0,0,1,0,1]).reshape([10,1]) # 真实标签
2 y_pred = np.array([1,1,1,1,1,1,1,0,0,0,0]).reshape([10,1]) # 预测标签
3
4 # 完成以下计算
5
6 Accuracy =
7 Precision =
8 Recall =
9 FPR =
10 F1_score =
11
12 print('准确率为%.ff,精确率为%.3f,召回率为%.3f,假正率为%.3f,F1分数为%.3f'% (Accuracy, Precision, Recall, FPR, F1_score))
编写计算AUC的函数以及绘制ROC曲线的函数。
1def AUC_cal(y_true,p_pred):
2 # y_true:真实标签
3 # p_pred: 预测概率
4
5 # 完成该函数(会涉及几行代码,我们只规定将输出值赋值给AUC变量)
6
7 AUC =
8 return AUC
9
10y_true = np.array([1,1,0,1,1,1,0,0,1,0,1]).reshape([10,1]) # 真实标签
11p_pred = np.array([0.9,0.8,0.7,0.6,0.55,0.54,0.53,0.52,0.51,0.505]).reshape([10,1]) # 预测概率
12AUC_yp = AUC_cal(y_true,p_pred)
13print('AUC值为%.3f'%(AUC_yp))
14
15def ROC_plot(y_true,p_pred):
16 # y_true:真实标签
17 # p_pred: 预测概率
18
19 # 完成该函数(会涉及几行代码,本函数无需return任何结果,需要完成绘制ROC曲线)
Softmax回归模型#
\(\hspace{1.5em}\) 到此为止,我们主要针对二分类问题讨论了全连接神经网络模型的训练和评估方法。Softmax回归(Softmax Regression)是一种用于多分类问题的算法。在多分类问题中,模型需要输出一个概率分布,表示每个类别的可能性。Softmax回归可以看作是逻辑回归(Logistic Regression)在多分类问题上的推广。
\(\hspace{1.5em}\) Softmax函数可以将一个含任意实数的 \(K\) 维向量 \(\bz=(z_1,\ldots,z_K)\trans\) 转换成另一个 \(K\) 维实向量 \(\ba=(a_1,\ldots,a_K)\trans\),其中
对于 \(i=1,\ldots,K\),\(a_i\in(0,1)\),且 \(\sum_{i=1}^Ka_i=1\)。这使得Softmax函数可以用于将模型的输出解释为概率分布。具体地,如果有 \(K\) 个类别,Softmax回归会对模型输出的 \(K\) 个值(通常是线性模型的输出,即权重与输入特征的线性组合)应用Softmax函数,计算标签属于每个类别的条件概率。然后,模型通常使用交叉熵损失函数来评估预测概率分布与真实标签之间的差异,并通过梯度下降等优化算法来训练模型参数,以最小化损失函数。
\(\hspace{1.5em}\) 记 \(\by = (y_1,\ldots,y_K)\trans\) 为某样本标签的one-hot编码;若该样本的标签为 \(j\),则 \(\by\) 中的第 \(j\) 个元素为1,其他元素为0。Softmax回归对应的损失函数为:
其中,\(\btheta\) 表示模型的参数,\(\ba=(a_1,\ldots,a_K)\) 表示Softmax模型对该样本属于每个类别估计的概率值。为了简化符号,我们在 (36) 的右侧忽略了模型参数 \(\btheta\)。
\(\hspace{1.5em}\) 根据 \(\btheta\),我们可以得到如下结果:
根据 (37),我们可利用 梯度下降及其衍生算法 中提到的相关算法对模型参数进行迭代更新,直至收敛。
习题#
根据(35)完成由\(\bz\)到\(\ba\)的计算。
1 def softmax(z):
2 # z:z值
3 a = np.zeros_like(z)
4
5 # 完成该函数(会涉及几行代码,我们只规定将输出值赋值给a变量)
6
7
8 return a
9
10 z = np.array([1,2,3,4]) # z值
11 a = softmax(z)
12 print(a)
对于\(i\in\{1,\ldots,K\}\)以及\(j\in\{1,\ldots,K\}\),计算\(\partial a_i/\partial z_j\)。
编写函数,根据输入的\(\bz\)及其对应的\(\ba\),输出一个\(K\times K\)的矩阵,其中\((i,j)\)对应的元素为\(\partial a_i/\partial z_j\)。
1 def backP_az(z,a):
2 # z:z值
3 # a:对应的a值
4 K = len(z)
5 der = np.zeros((K,K))
6
7 # 完成该函数(会涉及几行代码)
8
9
10 return der
11
12 z = np.array([1,2,3,4]) # z值
13 a = softmax(z)
14 der = backP_az(z,a)
15 print(der)
全连接神经网络Python编程#
\(\hspace{1.5em}\) 我们在单一隐藏层神经网络--一般形式中已经介绍过只有一个隐藏层的全连接神经网络的前向传播和后向传播的基本运算过程。在本节中,我们将考虑一个二分类问题,并基于Python介绍一个对该模型的算法实现。
加载程序包#
\(\hspace{1.5em}\) 我们首先需要加载两个深度学习模型中常用的程序包
import numpy as np
import matplotlib.pyplot as plt # for plots # 重要的画图程序包。
生成数据集#
\(\hspace{1.5em}\) 我们考虑如下模型:
其中,\(\mbox{Bernoulli}(p)\) 为一个成功概率为 \(p\) 的伯努利分布,\(\bx_{i} = (x_{1i},x_{2i})\trans\),\(x_{1i} = r_{i}\cos(\theta_{i})\), \(x_{2i} = r_{i}\sin(\theta_{i})\),\(r_{i}\sim\mbox{Uniform}(0,2)\),\(\theta_{i}\sim\mbox{Uniform}(0,2\pi)\),\(\mbox{Uniform}(a,b)\) 为区间 \((a,b)\) 上的均匀分布,\(\lVert \bx\rVert = (x_1^2+x_2^2)^{1/2}\) 为向量 \(\bx=(x_1,x_2)\trans\) 的欧氏距离。显然,(38) 不满足经典逻辑模型(即一类特殊广义线性模型)的模型假设。
\(\hspace{1.5em}\) 接下来我们将根据 (38),编写产生数据的函数。
def train_data_generation_nn(n, rn):
# n: 样本量
# rn: 随机种子
np.random.seed(rn) #设置随机种子为 rn
r = np.random.uniform(0,2,(n,1)) #生成 r
theta2 = np.random.uniform(0,2*np.pi,(n,1)) #生成 theta
x = np.concatenate((r * np.cos(theta2), r * np.sin(theta2)),axis = 1) #生成 x
y = np.random.binomial(1, r/2, (n,1)) #生成 y
return x, y
\(\hspace{1.5em}\) 接下来我们对所产生的数据进行可视化。
x, y = train_data_generation_nn(1000, 100)
fig, ax = plt.subplots()
scatter = ax.scatter(x[:,0], x[:,1], c=y[:,0])
legend1 = ax.legend(*scatter.legend_elements(),
loc="lower right", title="类别")
ax.set_title('模拟生成的训练样本')
plt.rcParams["font.sans-serif"] = ['SimSong'] #设置中文字体
plt.show()
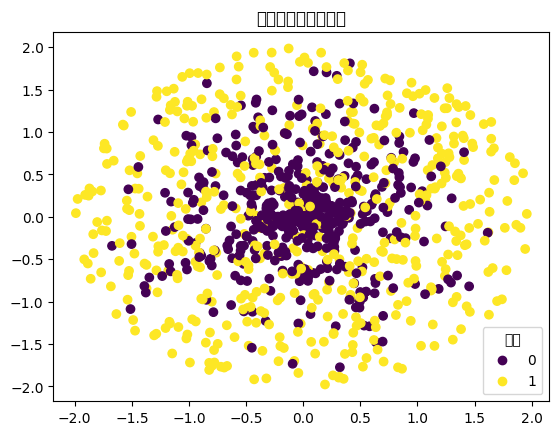
\(\hspace{1.5em}\) 根据可视化结果可知,我们无法从该数据集中看到一个线性边界能够对该数据集有很好的划分。因此,传统的逻辑回归模型无法对该数据集进行很好的拟合。
分步编写模型训练细节#
\(\hspace{1.5em}\) 我们将根据单一隐藏层神经网络--一般形式中所介绍的过程,编写一个只有一个隐藏层的全连接神经网络。具体地讲,我们将分步完成如下过程:
初始化模型参数。我们将对权重项进行随机初始化,而将每个神经元对应的偏置项初始化为0。
前向传播。基于当前模型参数进行前向传播,并缓存损失函数以及每层激活后的结果,即 \(\bA^{[1]}\) 以及 \(\bA^{[2]}\)。
后向传播。并缓存损失函数对模型参数的导数值。
参数更新。利用梯度下降方法对模型参数进行更新。
\(\hspace{1.5em}\) 第一步,我们对模型参数进行初始化。权重矩阵的每一行对应与神经元对应的权重向量。需要指出的是,我们通常将偏置项初始化为0,而用针对权重项利用随机初始化。
def Initialize_pars_nn(d,na,rn):
# d: 输入特征向量的维度
# na: 隐藏层神经元个数
# rn: 随机种子
np.random.seed(rn) #设置随机种子为 rn
W1 = np.random.normal(0,1,(na,d)) #随机初始化 W1
b1 = np.zeros((na,1)) #初始化 b1 为0
W2 = np.random.normal(0,1,(1,na)) #随机初始化 W2
b2 = np.zeros((1,1)) #初始化 b2 为0
par = {
'W1': W1,
'b1': b1,
'W2': W2,
'b2': b2,
}
return par
\(\hspace{1.5em}\) 第二步,基于当前模型参数,进行前向传播,并缓存损失函数以及每层激活后的结果。对于隐藏层,我们使用sigmoid函数进行激活。
def forward_nn(x, y, par):
# x: 特征向量构成的矩阵。在本例中,其规模为 n X 2
# y: 由标签组成的列向量。在本例中,其规模为 nX1
# par: 由当前参数值组成的字典.
W1 = par["W1"] #从字典 par 中获得 W1
b1 = par["b1"] #从字典 par 中获得 b1
W2 = par["W2"] #从字典 par 中获得 W2
b2 = par["b2"] #从字典 par 中获得 b2
Z1 = x @ W1.transpose() + b1.transpose() #计算 Z1
A1 = sigmoid(Z1) #计算 A1
Z2 = A1 @ W2.transpose() + b2 #计算 Z2
A2 = sigmoid(Z2) #计算 A2
J = - np.mean(y * np.log(A2) + (1-y) * np.log(1-A2)) #计算损失函数
cache = { #缓存 J, A1 以及 A2
'J': J,
'A1': A1,
'A2': A2
}
return cache
\(\hspace{1.5em}\) 接下来,我们编写后向传播函数。
def backprop_nn(x, y, par, cache):
# x: 特征向量构成的矩阵。在本例中,其规模为 n X 2
# y: 由标签组成的列向量。在本例中,其规模为 nX1
# par: 由当前参数值组成的字典.
# cache: 缓存了 J, A1 以及 A2 的字典
n = x.shape[0] #获得样本量 n
A1 = cache['A1'] #从字典 cache 中获得 A1
A2 = cache['A2'] #从字典 cache 中获得 A2
dZ2 = (A2 - y)/n #计算导数 dZ2
dW2 = dZ2.transpose() @ A1 #计算导数 dW2
db2 = np.sum(dZ2, keepdims=True) #计算导数 db2
dZ1 = (dZ2 @ par['W2']) * (A1*(1-A1)) #计算导数 dZ1
dW1 = dZ1.transpose() @ x #计算导数 dW1
db1 = np.sum(dZ1,axis = 0, keepdims = True).transpose() #计算导数 db1
grad = { #缓存 dW1, db1, dW2, db2
'dW1': dW1,
'db1': db1,
'dW2': dW2,
'db2': db2,
}
return grad
\(\hspace{1.5em}\) 接下来,利用梯度下降法更新模型参数值。
def update_par_nn(par, grad, alpha):
# par: 由当前参数值组成的字典
# grad: 包含导数结果的字典
# alpha: 学习率
par['W1'] -= alpha * grad['dW1'] #更新 W1
par['b1'] -= alpha * grad['db1'] #更新 b1
par['W2'] -= alpha * grad['dW2'] #更新 W2
par['b2'] -= alpha * grad['db2'] #更新 b2
return par
整合#
\(\hspace{1.5em}\) 我们对上面所编写的函数进行整合。
def est_par_nn(x, y, na, alpha, M, rn):
# x: 特征向量构成的矩阵。在本例中,其规模为 n X 2
# y: 由标签组成的列向量。在本例中,其规模为 nX1
# na: 隐藏层神经元个数
# alpha: 学习率
# M: 梯度下降算法中最多迭代次数
# rn: 初始化所用到的随机种子
d = x.shape[1] #获得输入特征的维度
par = Initialize_pars_nn(d,na, rn) #初始化模型参数
for i in range(M):
cache = forward_nn(x, y, par) #前向传播
grad = backprop_nn(x, y, par, cache) #后向传播
par = update_par_nn(par, grad, alpha) #参数更新
if i % 2000 == 1999:
print("After %4d iterations, the cost is %10.8f" % (i+1, cache['J'])) #监控损失函数
return par
模型拟合及分类估计#
\(\hspace{1.5em}\) 首先,我们将生成一个样本量为1000的训练集,并基于该训练集对模型参数进行估计。在这个过程中,我们需要提供一个名为sigmoid的函数。
def sigmoid(x):
# x: input
sig = 1/(1 + np.exp(-x))
return sig
x, y = train_data_generation_nn(1000, 100)
par = est_par_nn(x, y, 4, 0.01, 10000, 1234)
After 2000 iterations, the cost is 0.68699501
After 4000 iterations, the cost is 0.67412201
After 6000 iterations, the cost is 0.66199835
After 8000 iterations, the cost is 0.64818638
After 10000 iterations, the cost is 0.63323249
\(\hspace{1.5em}\) 根据训练好的模型参数,我们将编写一个用于估计给定特征向量时,\(y\) 属于类别1的条件概率(对应于本模型的A2)。
def prediction_nn(x_test, par):
# x_new: 规模为 n_test X 2 的测试集
# par: 训练好的模型参数字典
W1 = par["W1"] #从字典 par 中获得 W1
b1 = par["b1"] #从字典 par 中获得 b1
W2 = par["W2"] #从字典 par 中获得 W2
b2 = par["b2"] #从字典 par 中获得 b2
Z1 = x_test @ W1.transpose() + b1.transpose() # W1 X + b1 #计算Z1
A1 = sigmoid(Z1) #计算A1
Z2 = A1 @ W2.transpose() + b2 #计算Z2
A2 = sigmoid(Z2) #计算A2
return A2
\(\hspace{1.5em}\) 对训练好的模型进行可视化。预测的概率值大于0.5对应于1类,否则对应于0类。
x1_margin = np.linspace(-2.5,2.5,200)
x2_margin = np.linspace(-2.5,2.5,200)
x1_grid, x2_grid = np.meshgrid(x1_margin,x2_margin)
x_test = np.c_[x1_grid.ravel(), x2_grid.ravel()]
y_pred = prediction_nn(x_test, par)
y_pred[y_pred>=0.5]=1
y_pred[y_pred<0.5]=0
y_cont = y_pred.reshape(x1_grid.shape)
plt.contourf(x1_grid, x2_grid, y_cont, cmap=plt.cm.Spectral)
scatter = plt.scatter(x[:,0], x[:,1], c = y[:,0], cmap=plt.cm.Spectral,s=0.5)
plt.legend(*scatter.legend_elements()) # add legend
plt.show()
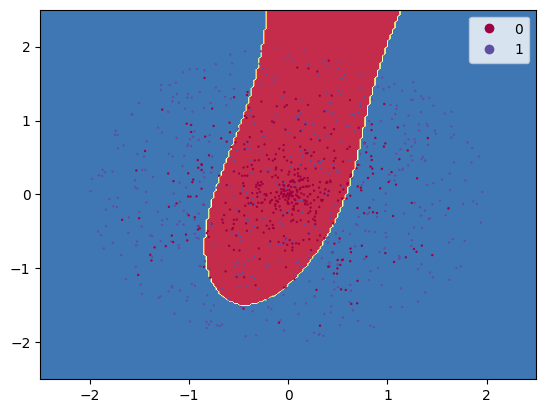
\(\hspace{1.5em}\) 通过观察拟合结果,我们可以得到如下结论。尽管我们使用了全连接神经网络模型,但其拟合效果并不理想。接下来,我们将隐藏层神经元个数增加到10个,并重新训练模型,并对结果进行可视化。
x, y = train_data_generation_nn(1000, 100)
par = est_par_nn(x, y, 10, 0.01, 10000, 1234)
y_pred = prediction_nn(x_test, par)
y_pred[y_pred>=0.5]=1
y_pred[y_pred<0.5]=0
y_cont = y_pred.reshape(x1_grid.shape)
plt.contourf(x1_grid, x2_grid, y_cont, cmap=plt.cm.Spectral)
scatter = plt.scatter(x[:,0], x[:,1], c = y[:,0], cmap=plt.cm.Spectral,s=0.5)
plt.legend(*scatter.legend_elements()) # add legend
plt.show()
After 2000 iterations, the cost is 0.68495977
After 4000 iterations, the cost is 0.67337237
After 6000 iterations, the cost is 0.66086113
After 8000 iterations, the cost is 0.64596488
After 10000 iterations, the cost is 0.62926999
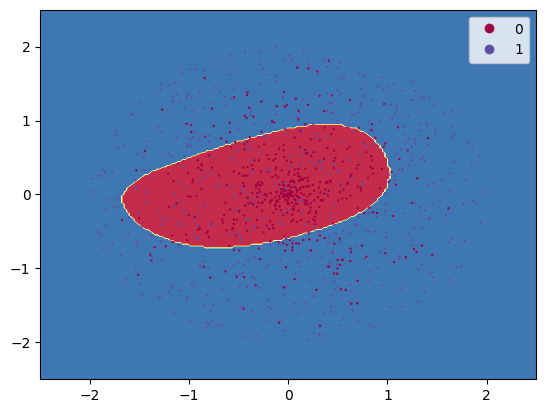
\(\hspace{1.5em}\) 当隐藏层神经元个数增加到10时,我们得到的结果较为理想。在参数进行了10000次迭代后,模型对应的损失函数约为0.63。
与逻辑回归模型的比较#
\(\hspace{1.5em}\) 接下来,我们编写 逻辑回归模型 的估计过程,并计算其对应的损失函数。我们在前面章节介绍过,逻辑回归模型是最简单的全连接神经网络。因此,我们将利用全连接神经网络模型的编写思路,编写逻辑回归模型的训练和估计过程。
def Initialize_pars(d,rn):
# d: 特征向量的维度
# rn: 随机种子
np.random.seed(rn) #设置随机种子为 rn
w = np.random.normal(0,1,(d,1)) # 由于逻辑回归模型的损失函数为凸函数,我们可以将权重向量初始化为0
b = np.zeros((1,1)) #初始化 b (其规模为 (1,1))
par = {
'w': w,
'b': b
}
return par
def forward(x, y, par):
# x: 特征向量构成的矩阵。在本例中,其规模为 n X 2
# y: 由标签组成的列向量。在本例中,其规模为 nX1
# par: 由当前参数值组成的字典.
n = x.shape[0] #获得样本量 n
Z = x @ par['w'] + par['b'] #计算Z
A = sigmoid(Z) #计算A
J = - (y * np.log(A) + (1-y) * np.log(1-A)).transpose() @ np.ones((n,1))/n #计算损失函数
cache = { #缓存 J 和 A
'J': J,
'A': A
}
return cache
def backprop(x, y, cache):
# x: 特征向量构成的矩阵。在本例中,其规模为 n X 2
# y: 由标签组成的列向量。在本例中,其规模为 nX1
# cache: 缓存了 J 以及 A 的字典
n = x.shape[0] #获得样本量n
err = (cache['A'] - y)/n #计算 dA
dw = (x.transpose() @ err) #计算 dw
db = (err.transpose() @ np.ones((n,1))) #计算 db
grad = { #缓存导数 dw 和 db
'dw': dw,
'db': db
}
return grad
def update_par(par, grad, alpha):
# par: 由当前参数值组成的字典
# grad: 包含导数结果的字典
# alpha: 学习率
par['w'] -= alpha * grad['dw'] #更新w
par['b'] -= alpha * grad['db'] #更新b
return par
def est_par_logistic(x, y, alpha, M, rn):
# x: 特征向量构成的矩阵。在本例中,其规模为 n X 2
# y: 由标签组成的列向量。在本例中,其规模为 nX1
# alpha: 学习率
# M: 梯度下降算法中最多迭代次数
# rn: 初始化所用到的随机种子
d = x.shape[1] #得到特征向量的维度
par = Initialize_pars(d,rn) #初始化模型参数
for i in range(M):
cache = forward(x, y, par) #前向传播
grad = backprop(x, y, cache) #后向传播
par = update_par(par, grad, alpha) #参数更新
if i % 2000 == 1999:
print("After %4d iterations, the cost is %10.8f" % (i+1, cache['J']))
return par
\(\hspace{1.5em}\) 基于我们已经得到的训练集,对逻辑回归模型进行训练。
par = est_par_logistic(x, y, 0.005, 10000, 1234)
After 2000 iterations, the cost is 0.69894689
After 4000 iterations, the cost is 0.69277831
After 6000 iterations, the cost is 0.69251881
After 8000 iterations, the cost is 0.69250782
After 10000 iterations, the cost is 0.69250734
\(\hspace{1.5em}\) 同样对模型参数进行10000次迭代更新,逻辑回归模型对应的损失函数约为0.69,其明显大于神经网络模型对应的0.63。下面我们对训练好的逻辑回归模型进行可视化。
x1_margin = np.linspace(-2.5,2.5,200)
x2_margin = np.linspace(-2.5,2.5,200)
x1_grid, x2_grid = np.meshgrid(x1_margin,x2_margin)
y_grid = sigmoid(par['b'] + par['w'][0] * x1_grid + par['w'][1]*x2_grid)
y_grid[y_grid>=0.5] = 1
y_grid[y_grid<0.5] = 0
plt.contourf(x1_grid, x2_grid, y_grid, cmap=plt.cm.Spectral)
scatter = plt.scatter(x[:,0], x[:,1], c = y[:,0], cmap=plt.cm.Spectral,s=1)
plt.legend(*scatter.legend_elements()) # add legend
plt.show()
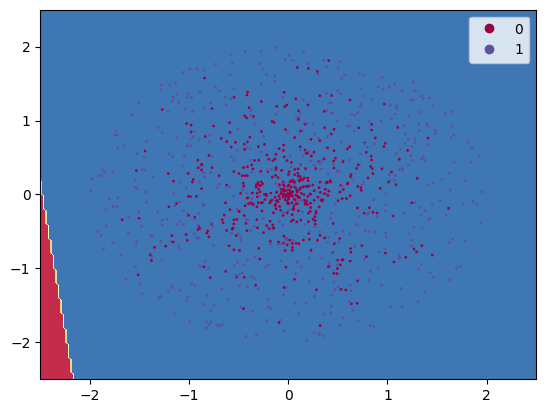
\(\hspace{1.5em}\) 可见,逻辑回归模型无法对该训练样本进行有效的拟合。
习题#
根据本节所涉及的程序,针对二分类模型,完成具有一般结构的全连接神经网络,并完成训练。针对本问题,我们只要求用户输入每层神经元的个数。例如,\(d = [3,3,4,3,1]\)对应一个具有四层的全连接神经网络模型,其中输入层为3维特征,第一层有3个神经元,第二层有四个神经元,第三层有3个神经元,输出层有一个神经元对应于标签为1的条件概率。
神经网络在干什么?以MNIST数据集为例#
\(\hspace{1.5em}\) 在之前的章节中,我们介绍了神经网络的基本概念、以及如何对其进行编程。一个自然的问题是,训练之后的神经网络内部发生了什么?在这一章节中,我们以MNIST数据集为例,依托用torch展示神经网络的内部工作机制,并借此简单介绍torch的基本用法。
加载程序包#
\(\hspace{1.5em}\) 在这里,我们加载一些必要的程序包,并设置随机数种子。
import numpy as np
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
# 设置随机数种子
np.random.seed(42)
torch.manual_seed(42)
# torch.cuda.manual_seed_all(42) # 如果使用GPU
\(\hspace{1.5em}\) 在上面的代码中,我们加载了torch和torchvision两个程序包,其中torch是PyTorch的核心程序包,torchvision是PyTorch的一个图像处理程序包。 torch需要单独设置随机数种子,以保证实验的可重复性。如果使用GPU,还需要设置torch.cuda.manual_seed_all(42)来设置GPU的随机数种子。
MNIST数据集#
\(\hspace{1.5em}\) MNIST数据集是一个手写数字数据集,包含了60000个训练样本和10000个测试样本。每个样本是一个28x28的灰度图像,表示一个0-9的数字。在这里,我们使用torchvision来加载MNIST数据集,并展示每个类别下的第一张图片。
1# 加载训练集和测试集
2trainset = datasets.MNIST('~/.pytorch/MNIST_data/', download=True, train=True,
3 transform=transforms.ToTensor())
4trainloader = DataLoader(trainset, batch_size=64, shuffle=True)
5
6testset = datasets.MNIST('~/.pytorch/MNIST_data/', download=True, train=False,
7 transform=transforms.ToTensor())
8testloader = DataLoader(testset, batch_size=64, shuffle=False)
9
10# 展示每个类别下的第一张图片
11fig, axs = plt.subplots(2, 5, figsize=(10, 5))
12for i in range(10):
13 axs[i//5, i%5].imshow(np.array(trainset.data[trainset.targets==i][0]), cmap='gray')
14 axs[i//5, i%5].set_title(f'Class {i}')
15 axs[i//5, i%5].axis('off')
16plt.show()

\(\hspace{1.5em}\) 在代码中,我们首先使用datasets.MNIST加载MNIST数据集,其中train=True表示加载训练集,train=False表示加载测试集。transforms.ToTensor()表示将图像数据转换为张量。接着,我们使用DataLoader将数据集转换为可迭代的数据加载器,以便于后续的训练和测试。
网络搭建#
\(\hspace{1.5em}\) 在这里,我们搭建一个简单的全连接神经网络。尽管对于图像数据,全连接神经网络并不是最好的选择,之后的章节也会介绍专门用于图像数据的 卷积神经网络。但在这里,为了更好的展示神经网络的内部工作机制,我们仍然使用全连接神经网络。同时我们也将看到,由于MNIST数据集的简单性,即使是一个简单的全连接神经网络也能取得不错的效果。
\(\hspace{1.5em}\) 和之前手动实现的全连接神经网络不同,我们在这里使用PyTorch提供的nn.Module类来搭建神经网络,大大简化了神经网络的搭建过程。在将来的编程实验中,我们也是用这个模块实现不同神经网络的搭建。
1class FNN(nn.Module):
2 def __init__(self):
3 super(FNN, self).__init__()
4 self.fc1 = nn.Linear(28*28, 128)
5 self.fc2 = nn.Linear(128, 64)
6 self.fc3 = nn.Linear(64, 10)
7
8 def forward(self, x):
9 x = x.view(-1, 28*28)
10 x = torch.relu(self.fc1(x))
11 x = torch.relu(self.fc2(x))
12 x = self.fc3(x)
13 return x
\(\hspace{1.5em}\) 在上面的代码中,我们首先定义了一个继承自nn.Module的类FNN。在__init__方法中,我们定义了三个全连接层,分别是输入层到隐藏层、隐藏层到隐藏层和隐藏层到输出层。在forward方法中,我们首先将输入的图像数据展平为一维张量,然后通过三个全连接层,最后输出一个10维的张量,表示每个类别的得分。在之前的章节中,对于二分类问题,我们在最终的输出层使用了Sigmoid激活函数。但在多分类问题中,我们通常使用 (36) 所示的Softmax激活函数;参见 Softmax回归模型 对该激活函数的讨论。但是在利用torch搭建神经网络时,我们通常不显式地定义Softmax激活函数,而是在损失函数中使用nn.CrossEntropyLoss,它内部已经包含了Softmax激活函数。
训练与测试函数#
\(\hspace{1.5em}\) 在这里,我们定义了一个训练函数train和一个测试函数test。在训练函数中,我们首先将模型设置为训练模式,然后遍历数据集,计算模型的输出和损失,最后更新模型的参数。在测试函数中,我们将模型设置为评估模式,然后遍历数据集,计算模型的输出和损失。
\(\hspace{1.5em}\) 首先,我们定义一个训练函数train
1def train(model, train_loader, criterion, optimizer, num_epochs):
2 model.train()
3 for epoch in range(num_epochs):
4 for batch_idx, (data, target) in enumerate(train_loader):
5 optimizer.zero_grad()
6 output = model(data)
7 loss = criterion(output, target)
8 loss.backward()
9 optimizer.step()
10 if batch_idx % 100 == 0:
11 print(f'Epoch {epoch+1}/{num_epochs}, Batch {batch_idx}, Loss: {loss.item():.4f}')
\(\hspace{1.5em}\) 在上面的代码中,我们首先将模型设置为训练模式,然后遍历数据集。在每个批次中,我们首先将优化器的梯度清零,然后计算模型的输出和损失,接着反向传播并更新模型的参数。在每个epoch中,我们打印出当前的epoch、batch和损失。
\(\hspace{1.5em}\) 接着,我们定义一个测试函数test
1def test(model, test_loader, criterion):
2 model.eval()
3 test_loss = 0
4 correct = 0
5 with torch.no_grad():
6 for data, target in test_loader:
7 output = model(data)
8 test_loss += criterion(output, target).item()
9 pred = output.argmax(dim=1, keepdim=True)
10 correct += pred.eq(target.view_as(pred)).sum().item()
11 test_loss /= len(test_loader.dataset)
12 accuracy = 100. * correct / len(test_loader.dataset)
13 print(f'Test Loss: {test_loss:.4f}, Accuracy: {accuracy:.2f}%')
\(\hspace{1.5em}\) 在上面的代码中,我们首先将模型设置为评估模式,然后遍历数据集。在每个批次中,我们计算模型的输出和损失,然后统计预测正确的样本数。最后,我们计算测试集的平均损失和准确率。
初始化模型和优化器#
\(\hspace{1.5em}\) 在这里,我们初始化一个模型和一个优化器。我们使用之前定义的FNN类来初始化一个模型,使用nn.CrossEntropyLoss作为损失函数,使用optim.Adam作为优化器。
model = FNN()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.003)
\(\hspace{1.5em}\) 到此为止,我们已经完成了神经网络的搭建、数据集的加载、训练与测试函数的定义以及模型和优化器的初始化。接下来,我们将训练和测试这个神经网络,并观察神经网络的内部工作机制。
1train(model, trainloader, criterion, optimizer, 100)
\(\hspace{1.5em}\) 在训练过程中,我们打印出了每个epoch和batch的损失。可以看到,随着训练的进行,损失逐渐减小,最终趋于0。
Epoch 1/100, Batch 0, Loss: 2.2923
Epoch 1/100, Batch 100, Loss: 0.5469
Epoch 1/100, Batch 200, Loss: 0.3759
Epoch 1/100, Batch 300, Loss: 0.2229
Epoch 1/100, Batch 400, Loss: 0.1669
Epoch 1/100, Batch 500, Loss: 0.1417
Epoch 1/100, Batch 600, Loss: 0.0689
Epoch 1/100, Batch 700, Loss: 0.1060
Epoch 1/100, Batch 800, Loss: 0.1921
Epoch 1/100, Batch 900, Loss: 0.2093
Epoch 2/100, Batch 0, Loss: 0.1010
...
Epoch 100/100, Batch 600, Loss: 0.0000
Epoch 100/100, Batch 700, Loss: 0.0000
Epoch 100/100, Batch 800, Loss: 0.0000
Epoch 100/100, Batch 900, Loss: 0.0000
\(\hspace{1.5em}\) 接着,我们测试这个神经网络
1test(model, testloader, criterion)
Test Loss: 0.0070, Accuracy: 97.66%
\(\hspace{1.5em}\) 从测试结果中,我们可以看到,即便是一个简单的全连接神经网络,也能在MNIST测试集上取得97.66%的准确率。这表明了神经网络的强大特征提取能力。
参数和输出的提取#
\(\hspace{1.5em}\) 我们使用model.named_parameters()来提取神经网络的参数。这个方法返回一个迭代器,迭代器的每个元素是一个元组,包含了参数的名字和参数的值。
1for name, param in model.named_parameters():
2 print(name, param.size())
fc1.weight torch.Size([128, 784])
fc1.bias torch.Size([128])
fc2.weight torch.Size([64, 128])
fc2.bias torch.Size([64])
fc3.weight torch.Size([10, 64])
fc3.bias torch.Size([10])
\(\hspace{1.5em}\) 在上面的代码中,我们打印出了每个全连接层的权重和偏置的大小。可以看到,第一个全连接层的权重大小为torch.Size([128, 784]),表示有128个神经元,每个神经元有784个输入。第一个全连接层的偏置大小为torch.Size([128]),其他全连接层的权重和偏置的大小也可以类似地解释。
\(\hspace{1.5em}\) 接下来,我们从测试集中,选取每个类别的第一个样本,并提取这些样本的数据和标签。
1# 从测试集中选取样本
2targets = testset.targets
3data = testset.data
4
5# 选取每个类别的第一个样本
6list_idx = []
7for i in range(10):
8 idx = np.where(targets == i)[0][0]
9 list_idx.append(idx)
10data_selected = data[list_idx].float()
11targets_selected = targets[list_idx]
12print(targets_selected)
tensor([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
\(\hspace{1.5em}\) 之后,我们手动对这些样本进行一次前向传播,从而提取每个全连接层的输出。
1with torch.no_grad():
2out_put_1 = torch.relu(model.fc1(data_selected.view(-1, 28*28)))
3out_put_2 = torch.relu(model.fc2(out_put_1))
4out_put_3 = torch.softmax(model.fc3(out_put_2), dim=1)
5
6print(out_put_3.argmax(dim=1))
tensor([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
\(\hspace{1.5em}\) 在上面的代码里,我们在最后一层全连接层的输出上使用了Softmax激活函数,将输出转换为“概率”。最后,我们打印出了每个样本的预测类别。可以看到,神经网络成功地将每个样本正确地分类。
神经网络的内部工作机制#
\(\hspace{1.5em}\) 让我们以一张手写数字“2”的图片为例,来展示一张图片是如何转化为预测结果的。
\(\hspace{1.5em}\) 上面这个视频展示了,图片被拉直为一维张量输入进神经网络后,每层的输出和权重情况。视频中的每个圆圈代表一个神经元,圆圈的颜色代表了神经元的激活程度,圆圈越亮代表激活程度越高。每个线段代表一个权重,线段的亮度代表了权重的绝对大小,红色代表正权重,蓝色代表负权重。 可以看到,大部分的线段颜色都是蓝色,即大部分的权重都是负值。MNIST数据集中,每个像素的取值都在\([0,1]\)之间,这就使得经过ReLU激活函数之后(回忆ReLU激活函数的形式),大部分神经元的输出都是0,因而并未被激活。这个例子充分说明了ReLU激活函数的优点:稀疏激活。这种由ReLU导致了神经网络的稀疏性,降低了神经网络的复杂度,减小了过拟合的风险。